

By Patrik Marton
この記事は、2022/3/15に公開された「Reliable Data Exchange with the Outbox Pattern and Cloudera DiM」の翻訳です。
この記事では、Cloudera Data Platform (CDP) とそのストリーミングソリューションを使用して、最新アプリケーションで、大規模なマイクロサービス間の信頼性の高いデータエクスチェンジを設定し、最高負荷下でも内部の整合性を確保する方法をご紹介します。
はじめに
最新アプリケーション設計の多くは、イベントドリブンです。イベントドリブン型のアーキテクチャは、結合が最小限になるので、現代の大規模分散システムに最適な選択肢となります。マイクロサービスでは、ビジネスロジックの一環として、データを自分のローカルストレージに永続化するだけでなく、イベントを発生させて内部状態の変化を他のサービスに通知する必要がある場合があります。データベースへの書き込みやメッセージバスへのメッセージ送信はアトミックではありません。つまりこれらの操作のいずれかが失敗すると、アプリケーションが不整合の状態となります。Transactional Outbox パターンは、サービスが安全かつアトミックな方法でこれらの操作を実行し、アプリケーションの整合性を保つためのソリューションを提供します。
この記事の中では、Cloudera Public Cloud を使用して、Spring Boot マイクロサービスとストリーミングクラスタのデモ環境をセットアップします。
Outbox Pattern
このパターンの一般的な考え方は、サービスのデータストアに “outbox” テーブルを用意することです。サービスがリクエストを受け取ると、新しいエンティティを永続化するだけでなく、イベントバスに公開されるメッセージを表すレコードも永続化します。この方法では、2つのステートメントは同じトランザクションの一部となり、最近のデータベースはアトミック性を保証しているので、トランザクションは成功するか完全に失敗するかのどちらかです。
“outbox” テーブルのレコードには、アプリケーション内部で発生したイベントに関する情報と、さらなる処理またはルーティングに必要なメタデータが含まれています。このレコードには厳密なスキーマはありませんが、イベントを適切な方法で処理しルーティングできるようにするためには、共通のインターフェースを定義する価値があることがわかります。トランザクションがコミットされると、レコードは外部のコンシューマが利用できるようになります。
この外部コンシューマは、 “outbox” テーブルやデータベースのログをスキャンして新しいエントリーを探し、Apache Kafka などのイベントバスにメッセージを送信する非同期プロセスであることができます。Kafka には Kafka Connect が付属しているので、例えば PostgreSQL 用の Debeziumコネクタなど、あらかじめ用意されているコネクタの機能を活用して、変更データキャプチャ (CDC) 機能を実装することができます。
シナリオ
ユーザーが特定の商品を注文できる簡単なアプリケーションを想像してみましょう。OrderService は、ユーザーが送信したばかりの注文詳細のリクエストを受け取ります。本サービスは、データに対して以下の操作を行うために必要です。
- 注文データを独自のローカルストレージに永続化する。
- 新しい注文を他のサービスに通知するためのイベントを送信する。これらのサービスは、在庫の確認 (例:InventoryService) や支払いの処理 (例:PaymentService) を担当することがある。
必要な2つのステップはアトミックではないので、片方が成功してももう片方が失敗することもあり得ます。これらの障害は、予期せぬシナリオを引き起こし、最終的にはアプリケーションの状態が破損する可能性があります。
最初の失敗シナリオでは、OrderService がデータを正常に永続化したが、メッセージを Kafka にパブリッシュする前に失敗した場合、アプリケーションの状態は不整合になります。
同様に、データベースのトランザクションが失敗しても、イベントが Kafka にパブリッシュされた場合、アプリケーションの状態は不整合になります。
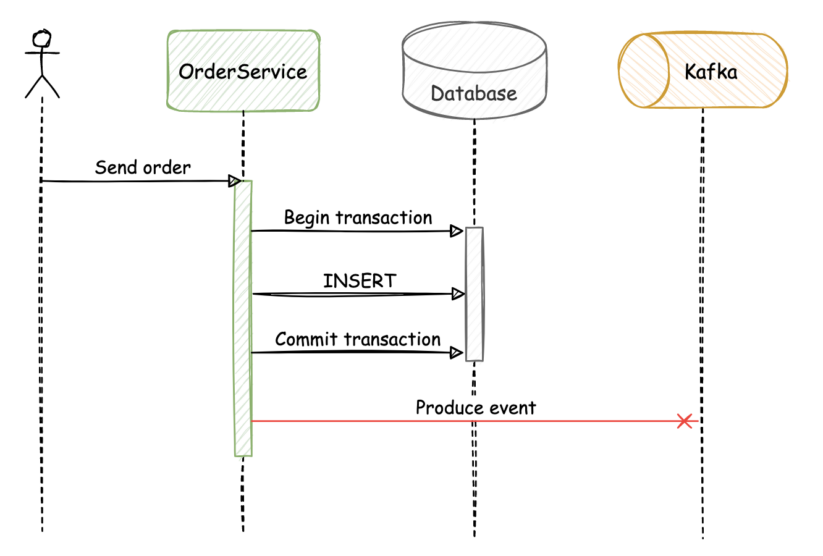
これらの整合性の問題を別の方法で解決することは、サービスのビジネスロジックに必要のない複雑さを加えることになり、同期的なアプローチを実装が必要になる場合があります。この方法の重要な欠点は、2つのサービス間の結合が増えることです。さらに、新しいコンシューマがイベントストリームに参加して、最初からイベントを読むことができないことも欠点です。
同じフローに outbox を実装すると、次のようになります。
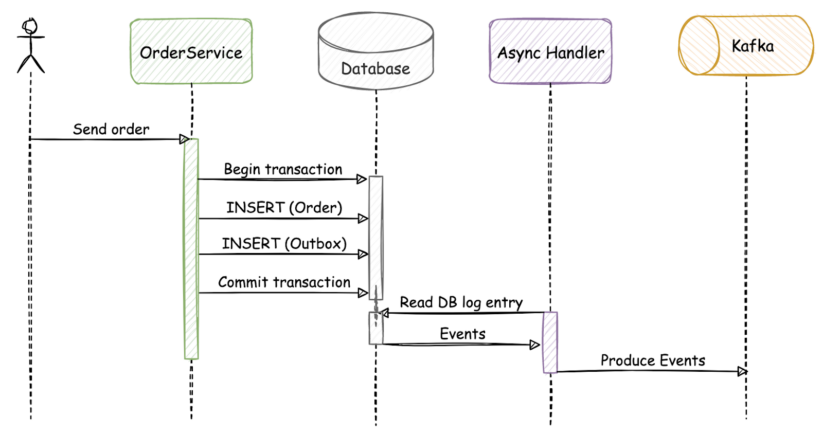
このシナリオでは、 “order” テーブルと “outbox” テーブルが同じアトミックトランザクションで更新されます。コミット成功後、データベースを継続的に監視する非同期イベントハンドラーが行レベルの変更に気付き、Kafka Connect を通じて Apache Kafka にイベントを送信します。
Cloudera Public Cloud と Debezium をベースにした実装
デモアプリケーションのソースコードは github で公開されています。この例では、注文サービスがユーザーから新しい注文要求を受け取り、新しい注文をローカルデータベースに保存し、イベントを発行し、最終的に Apache Kafka に送信されます。Spring フレームワークを使って Java で実装されています。ローカルストレージとして Postgres データベースを使用し、永続性を処理するためにSpring Data を使用しています。サービスとデータベースは、Docker コンテナで実行されます。
ストリーミングの部分は、Cloudera Data Platform with Public Cloud を使って、Streams Messaging DataHub をセットアップし、アプリケーションに接続しようと思っています。このプラットフォームでは、新しいワークロードクラスタのプロビジョニングとセットアップが非常に簡単に効率的に行えます。
注: Cloudera Data Platform (CDP) は、あらゆるクラウド、分析、データを自由に選択できるように設計されたハイブリッドデータプラットフォームです。CDP は、最適なパフォーマンス、拡張性、セキュリティ、およびガバナンスにより、あらゆる場所のデータに対して、より迅速かつ容易なデータ管理とデータ分析を実現します。
このソリューションのアーキテクチャは、ざっくりと次のようになります。
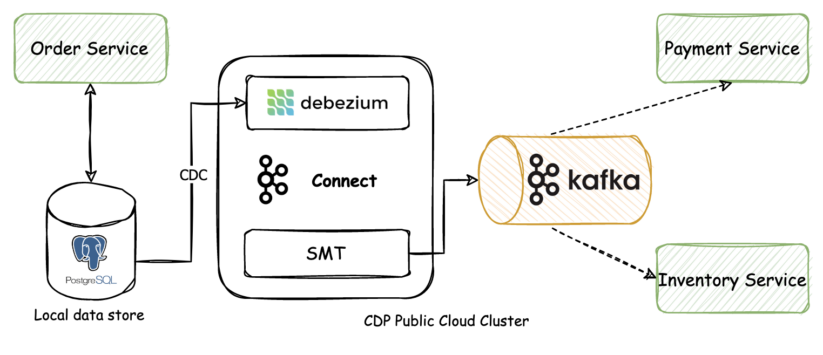
Outboxのテーブル
Outbox テーブルは、OrderService がローカルデータを保存するのと同じデータベースの一部です。データベーステーブルのスキーマを定義する際、メッセージを処理して Kafka にルーティングするために必要なフィールドは何かを考えることが重要です。outbox テーブルには、以下のスキーマが使用されます。
| Column | Type |
| uuid | uuid |
| aggregate_type | character varying(255) |
| created_on | timestamp without time zone |
| event_type | character varying(255) |
| payload | character varying(255) |
フィールドは以下のとおりです。
- uuid:レコードの識別子。
- aggregate_type:イベントの集計タイプ。関連するメッセージは同じ集約型を持ち、それを使ってメッセージを正しいKafkaトピックにルーティングすることができる。例えば、注文に関連するすべてのレコードは、集約タイプ “Order” を持つことができ、イベントルーターはこれらのメッセージを “Order” トピックにルーティングすることが容易になる。
- created_on:注文時のタイムスタンプ。
- event_type:イベントのタイプ。コンシューマが与えられたイベントを処理するかどうか、どのように処理するかを決定できるようにするために必要。
- payload:実際のイベントの内容。このフィールドのサイズは、要件とペイロードの最大予想サイズに基づいて調整する必要がある。
OrderService
OrderService はシンプルな Spring Boot のマイクロサービスで、2つのエンドポイントを公開しています。注文のリストを取得するための単純な GET エンドポイントと、新しい注文をサービスに送信するための POST エンドポイントがあります。POST エンドポイントのハンドラーは、新しいデータをローカルデータベースに保存するだけでなく、アプリケーション内部でイベントを発生させます。

このメソッドは、トランザクションアノテーションを使用します。このアノテーションにより、フレームワークがメソッドの周囲にトランザクションロジックを挿入することができます。これによって、2つのステップがアトミックに処理され、予期せぬ失敗の場合には、いかなる変更もロールバックされることを確認することができます。イベントリスナーは呼び出し元のスレッドで実行されるため、呼び出し元と同じトランザクションを使用します。

発生したイベントごとにイベントリスナー関数が呼び出され、新しい OutboxMessage エンティティが作成されてローカルデータベースに保存され、その後すぐに削除されます。迅速な削除の理由は、Debezium CDC ワークフローがデータベーステーブルの実際の内容を調べず、代わりに追記のみのトランザクションログを読み取るからです。save() メソッド呼び出しは、データベースログに INSERT エントリーを作成し、delete() 呼び出しは、DELETE エントリーを作成します。INSERT イベントごとに、Kafka にメッセージが転送されます。DELETE などの他のイベントは、今回のユースケースに有用な情報が含まれていないため、現在は無視することができます。レコードの削除が実用的であるもう1つの理由は、 “Outbox” テーブルのために追加のディスクスペースが必要ないことで、これは大規模なストリーミングシナリオで特に重要です。
トランザクションがコミットした後、レコードは Debezium で利用できるようになります。
ストリーミング環境の構築
ストリーミング環境を構築するために、CDP Public Cloud を使用して、7.2.16 – Streams Messaging Light Duty テンプレートを使用してワークロードクラスタを作成することにします。このテンプレートでは、ストリーミングクラスタが動作するようになっており、Debezium 関連の設定のみを行う必要があります。Cloudera は、7.2.15 (Cloudera Data Platform (CDP) パブリッククラウドリリース、Kafka 2.8.1+でサポート) 以降の Debezium コネクタを提供します。
ストリーミング環境では、以下のサービスが動作します。
- Apache KafkaとKafka Connect
- Zookeeper
- Streams Replication Manager
- Streams Messaging Manager
- Schema Registry
- Cruise Control
Debezium の設定方法を説明すると長くなるので、今回は割愛します。詳しくは Cloudera documentを参照ください。
コネクタの作成
ストリーミング環境と Debezium 関連の設定がすべて完了したら、コネクタの作成です。これには、SMM (Streams Messaging Manager) の UI を使いますが、オプションでコネクタの登録や処理を行う Rest API も用意されています。
コネクタが初めてサービスのデータベースに接続したとき、すべてのスキーマの整合性スナップショットが取得されます。スナップショットが完了した後、コネクタはデータベースにコミットされた行レベルの変更を継続的にキャプチャします。このコネクタは、データ変更イベントレコードを生成し、Kafka トピックにストリームします。
Cloudera 環境での定義済み json 設定のサンプルは次のようになります。
{ "connector.class": "io.debezium.connector.postgresql.PostgresConnector", "database.history.kafka.bootstrap.servers": "${cm-agent:ENV:KAFKA_BOOTSTRAP_SERVERS}", "database.hostname": "[***DATABASE HOSTNAME***]", "database.password": "[***DATABASE PASSWORD***]", "database.dbname": "[***DATABASE NAME***]", "database.user": "[***DATABASE USERNAME***]", "database.port": "5432", "tasks.max": "1",, "producer.override.sasl.mechanism": "PLAIN", "producer.override.sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"[***USERNAME***]\" password=\"[***PASSWORD***]\";", "producer.override.security.protocol": "SASL_SSL", "plugin.name": "pgoutput", "table.whitelist": "public.outbox", "transforms": "outbox", "transforms.outbox.type": "com.cloudera.kafka.connect.debezium.transformer.CustomDebeziumTopicTransformer", "slot.name": "slot1" }
上記の最も重要な構成について説明すると、次のとおりです。
- database.hostname: PostgreSQLデータベースサーバーのIPアドレスまたはホスト名
- database.user: データベースに接続するためのPostgreSQLデータベースユーザーの名前
- database.password: データベースに接続するためのPostgreSQLデータベースユーザーのパスワード
- database.dbname: 変更のストリーム元となるPostgreSQLデータベースの名前
- plugin.name: PostgreSQLサーバーにインストールされているPostgreSQL論理デコードプラグインの名前
- table.whitelist: Debeziumが変更を監視しているテーブルのホワイトリスト
- transforms: トランスフォーメーションの名前
- transforms.<transformation>.type: トランスフォーメーションのSMTプラグインクラス。 ここでは、ルーティングに使用。
SMM UI を使用してコネクタを作成する場合:
- SMM UI のホームページを開き、メニューから “Connect” を選択し、 “New Connector” をクリックし、ソーステンプレートから PostgresConnector を選択してください。
- “Import Connector Configuration… “をクリックし、コネクタの定義済み JSON 表現を貼り付け、”Import” をクリックします。
- 設定が有効で、コネクタがデータベースにログインできることを確認するために、”Validate” をクリックします。
- 設定が有効であれば、”Next” をクリックし、再度プロパティを確認した後、“Deploy” をクリックします。
- コネクタはエラーなく動作し始めるはずです。
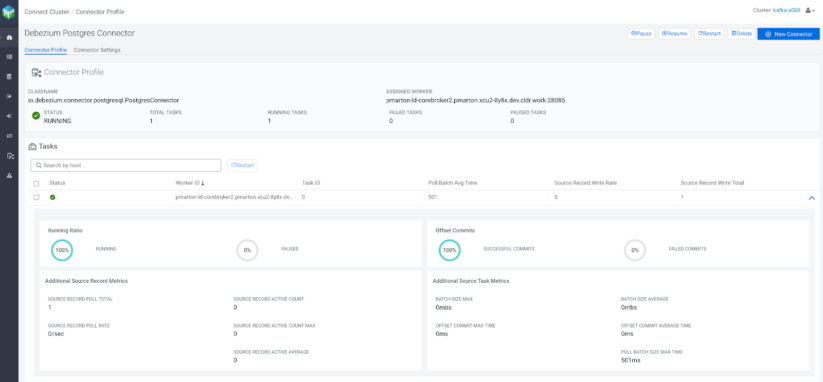
すべての準備が整ったら、OrderService はユーザーからのリクエストの受信を開始することができます。これらのリクエストはサービスによって処理され、メッセージは最終的に Kafka に行き着くことになります。メッセージにルーティングロジックが定義されていない場合、デフォルトのトピックが作成されます。
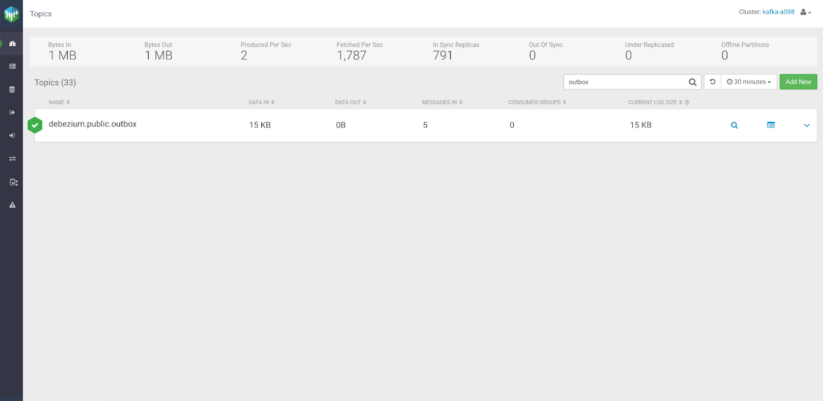
トピックルーティングのためのSMTプラグイン
トピックルーティングのロジックを定義しないと、Debezium は Kafka に “serverName.schemaName.tableName” という名前のデフォルトのトピックを作成することになります。
- serverName: “database.server.name” 構成プロパティで指定された、コネクタの論理名 。
- schemaName: 変更イベントが発生したデータベーススキーマの名前。 テーブルが特定のスキーマの一部でない場合、このプロパティは “public” になる。
- tableName: 変更イベントが発生したデータベーステーブルの名前。
この自動生成された名前は、いくつかのユースケースには適しているかもしれませんが、実際のシナリオでは、トピックに意味のある名前をつけるべきです。論理的に事象をトピックごとに分けることができないという問題もあります。
メッセージが Kafka Connect コンバーターに到達する前に、私たちが指定したロジックに基づいてメッセージをトピックに再ルーティングすることでこれを解決することができます。そのために、Debeziumは、SMT (Single Message Transform) プラグインが必要です。
シングルメッセージ変換は、Connect を流れるメッセージに適用されます。Kafka に書き込まれる前の受信メッセージや、シンクに書き込まれる前の送信メッセージの変換を行います。今回のケースでは、ソースコネクターで生成されたものの、まだ Kafkaに書き込まれていないメッセージを変換する必要があります。SMT にはさまざまなユースケースがありますが、私たちが必要とするのはトピックルーティングだけです。
outbox テーブルのスキーマには、”aggregate_type” というフィールドがあります。 受注関連メッセージの単純な集計タイプは、”Order” です。 このプロパティに基づき、プラグインは同じ集約タイプを持つメッセージを同じトピックに書き込む必要があることを認識します。集約型はメッセージごとに異なることがあるため、受信したメッセージをどこにルーティングするかは簡単に決めることができます。
トピックルーティングのための簡単な SMT の実装は次のようなものです。

操作種別は、Debezium変更メッセージから抽出することができます。削除、読み取り、更新の場合は、作成 (op=c) 操作にしか関心がないため、単にメッセージを無視します。”aggregate_type” に基づいて、宛先トピックを算出することができます。aggregate_type” の値が “Order” の場合、”orderEvents” トピックに送信されます。データで何ができるか、いろいろな可能性があることは容易に想像できますが、とりあえずスキーマとメッセージの値は、宛先トピック名とともにKafkaに送信されます。
SMT プラグインの準備ができたら、コンパイルしてjarファイルとしてパッケージ化する必要があります。jar ファイルは、Kafka Connect のプラグインパスに存在する必要があり、コネクタで利用できるようになります。Kafka Connect は、ディレクトリパスのカンマ区切りリストとして定義されたplugin.path ワーカー構成プロパティを使用して、プラグインを見つけます。
どの変換プラグインを使用するかをコネクタに伝えるには、以下のプロパティをコネクタ構成の一部にする必要があります。
| transforms | outbox |
| transforms.outbox.type | com.cloudera.kafka.connect.debezium.transformer.CustomDebeziumTopicTransformer |
SMTプラグインで新しいコネクタを作成した後、Debezium プロデューサーはデフォルトのトピックの代わりに orderEvents という新しいトピックを作成し、同じ集約型を持つ各メッセージをそこにルーティングします。
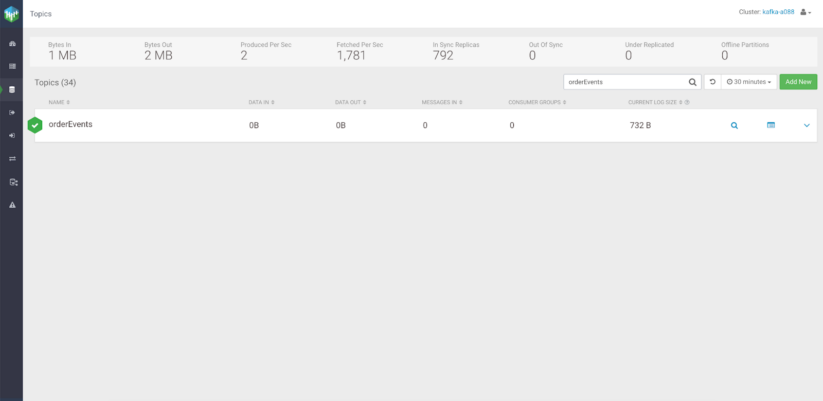
既存の SMT プラグインについては、Debezium documentation を確認してください。
集約タイプとパーティション
先ほど、outbox テーブルのスキーマを作成する際に、aggregate_type フィールドを使用して、イベントがどの集約ルートに関連しているのかを表示しました。ドメイン駆動設計と同じ考え方で、関連するメッセージをグループ化することができるのです。この値は、これらのメッセージを正しいトピックにルーティングするために使用することもできます。
同じドメインに属するメッセージを同じトピックに送ることは、それらを分離するのに役立ちますが、時には他のより強力な保証が必要です。例えば、同じパーティションに関連するメッセージがあり、それらが順番に消費されることができます。このため、outbox スキーマに aggregate_id を追加することができる。この ID は Kafka メッセージのキーとして使用され、SMT プラグインを少し変更するだけでよいのです。同じキーを持つメッセージは、すべて同じパーティションに送られます。これは、あるプロセスがトピックのパーティションのサブセットのみを読み取る場合、1つのキーに対するすべてのレコードが同じプロセスによって読み取られることを意味します。
1回の以上配信
アプリケーションが正常に動作しているとき、またはグレースフルシャットダウンの場合、コンシューマはメッセージを正確に1回見ることを期待できます。しかし、想定外のことが起きると、重複する事象が発生することがあります。
Debezium に予期せぬ障害が発生した場合、最後に処理したオフセットを記録できない場合があります。再開時には、最後に判明したオフセットが開始位置の決定に使用されます。同様のイベントの重複は、ネットワーク障害でも発生することがあります。
つまり、重複するメッセージはまれかもしれませんが、コンシュームするサービスはイベントを処理する際に重複することを予期する必要があります。
結果
この時点で、outbox パターンは完全に実装されています。OrderService はリクエストを受け取り、新しいエンティティをローカルストレージに永続化し、単一のアトミックトランザクションで Apache Kafka にイベントを送信し始めることができます。CREATE イベントは Kafka に書き込まれる前に Debezium で検出する必要があるため、このアプローチでは最終的に整合性が保たれることになります。つまり、コンシューマサービスはプロダクションサービスより少し遅れるかもしれませんが、このユースケースにおいては問題ないでしょう。これは、このパターンを使用する際に評価する必要があるトレードオフです。
また、このソリューションの中核に Apache Kafka があることで、他のマイクロサービスの非同期イベントドリブン処理も可能になります。新しいコンシューマは、適切なトピックの保持時間があれば、トピックの最初から読み、イベントの履歴に基づいてローカルな状態を構築することも可能です。また、単一コンポーネントの故障にも強いアーキテクチャです。何かが故障したり、あるサービスが一定時間利用できなかったりしても、メッセージは後で処理されるだけなので、リトライやサーキットブレーキングなど、同様の信頼性パターンを実装する必要がないのです。
実際に体験する
アプリケーションの開発者は、Cloudera Data Platformのデータ・イン・モーション・ソリューションを使用して、分散サービス間の信頼性の高いデータエクスチェンジを設定し、高負荷シナリオでもアプリケーションの状態が整合性していることを確認することができます。まずは、Cloudera Streams Messaging コンポーネントがパブリッククラウドでどのように機能するか、また、定義済みのクラスタテンプレートを使って、本番環境に適したワークロードクラスタをセットアップがどれだけ簡単であるかご確認ください。
さらに読む
CDP パブリッククラウドにおける Kafka Connect/Debezium を利用した MySQL CDC
Cloudera 環境におけるセキュアな Debezium コネクタの使用方法
Cloudera Data Platform で Kafka Connect を安全に使用する
