

by Navita Sood
この記事は、2023/03/17 に公開された「Educating ChatGPT on Data Lakehouse」の翻訳です。
ChatGPT の利用が浸透するにつれて、お客様やデータユーザーの議論の中で、ChatGPT の回答を引用している場面によく遭遇するようになりました。私は、皆さんのChatGPT に対する高い関心と、データレイクハウス、データメッシュ、データファブリックといった最新のデータアーキテクチャを学ぼうとする熱意をとても嬉しく感じています。ChatGPT は、あらゆる技術についてハイレベルな知見を広めたり、認識を得たりするための優れたリソースです。しかし、特定の技術を深く掘り下げる場合には、注意が必要です。それは、ChatGPT が過去のデータを基に学習している点、また、質問の仕方によっては不正確な情報や、誤解を招く回答が返ってくる可能性があることです。
ChatGPT の無料版 (2023年3月時点) を使い、データレイクハウスとその構成要素について簡単な質問をしてみました。今回のブログでは、間違っていた部分の指摘と、なぜそのような結果になったのかについて解明していきたいと思います。そして、このブログ記事から ChatGPT が学び、修正されれば、社会貢献にもなるのではと期待しています。
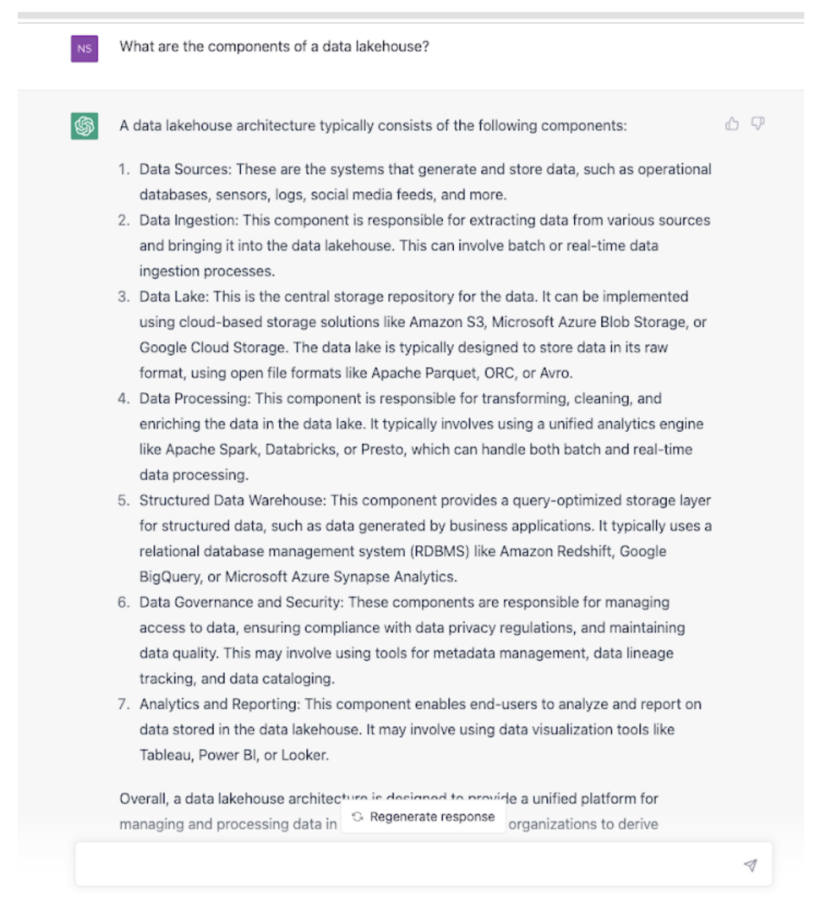 生成された答えはかなり充実していると言えます。1つ抜けている重要な要素は、レイクハウスデータにアクセスするすべての分析サービスで使用できる、共通の共有テーブルフォーマットについてです。データレイクハウスを実装する場合、テーブルフォーマットは抽象化レイヤーとして機能します。そして、あらゆるエンジンやツールでレイクハウス内のすべての構造化、非構造化データに簡単に同時アクセスできるようにするために重要な部分となります。テーブルフォーマットは、データレイクに不足している非構造化データに必要な構造を提供します。スキーマやメタデータ定義を使い、データウェアハウスに近づけるようにします。一般的なテーブルフォーマットには、Apache Iceberg、Delta Lake、Hudi、Hive ACID などがあります。
生成された答えはかなり充実していると言えます。1つ抜けている重要な要素は、レイクハウスデータにアクセスするすべての分析サービスで使用できる、共通の共有テーブルフォーマットについてです。データレイクハウスを実装する場合、テーブルフォーマットは抽象化レイヤーとして機能します。そして、あらゆるエンジンやツールでレイクハウス内のすべての構造化、非構造化データに簡単に同時アクセスできるようにするために重要な部分となります。テーブルフォーマットは、データレイクに不足している非構造化データに必要な構造を提供します。スキーマやメタデータ定義を使い、データウェアハウスに近づけるようにします。一般的なテーブルフォーマットには、Apache Iceberg、Delta Lake、Hudi、Hive ACID などがあります。
また、データレイクのレイヤは、クラウドオブジェクトストアに限定されません。多くの企業はまだ大量のデータをオンプレミスに保有しており、データレイクハウスはパブリッククラウドに限定されるものではありません。また、プライベートクラウド、HDFS ストア、Apache Ozone を活用し、オンプレミスやハイブリッド展開で構築することができます。
Cloudera では、機械学習もレイクハウスの一部として提供しています。データサイエンティストは、データレイクハウスの信頼できるデータに簡単にアクセスできるようになります。そして、新しい機械学習プロジェクトを迅速に立ち上げ、高度な分析のための新しいモデルを構築して展開できます。

このやり取りで、回答のはじめの部分は良いと思うのですが、残念ながら、すぐに機能の話に飛びつき、さらに機能の比較に関しては間違いがあります。どちらが優れたテーブルフォーマットかを判断する方法は、機能だけではありません。互換性、オープン性、汎用性など、多様なデータユーザーへの幅広い利用可能性、セキュリティとガバナンスの保証、アーキテクチャを将来的に保証できるかなどが関係してきます。
Delta Lake と Apache Iceberg の違いを詳しく知りたい方は、以下のハイレベルな機能比較表をご覧ください。
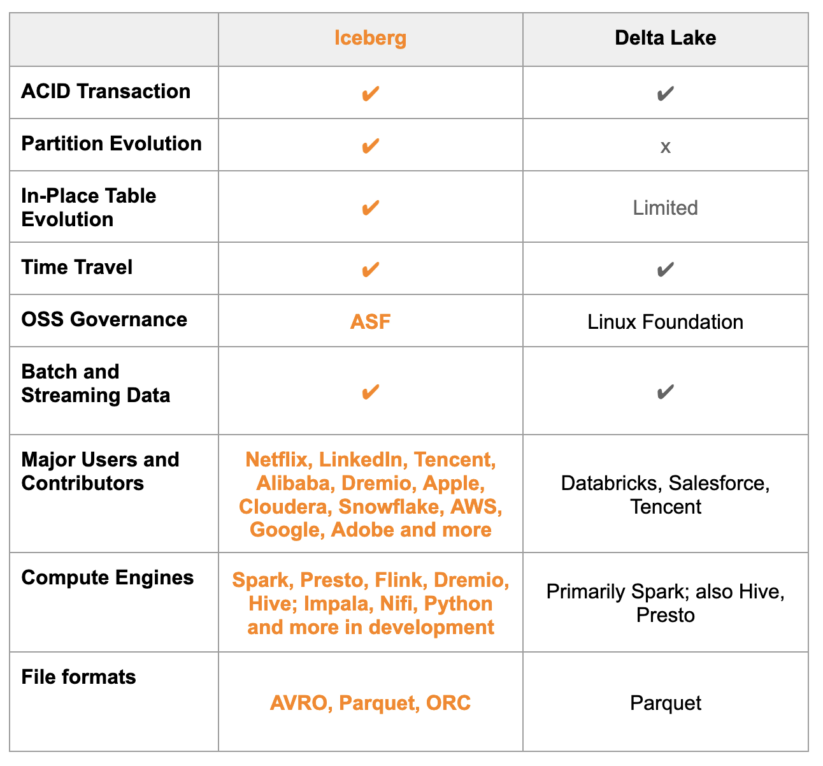

上記の回答では間違いがあり、誤解を生んでしまうという意味で危険です。ChatGPTがより深い分析に対応できないと感じる理由はこのような答えにあります。一見、理にかなった回答に見えますが、前提がおかしいので、この回答全体や他の回答についてもその正確さに疑問が出てきます。「Apache Iceberg の上に Delta Lake が構築されている」というのは、正しくありません。全く異なる無関係なテーブルフォーマットであり、お互いの構想とは関係ないのです。Apache Iceberg と Delta Lakeは、共通のデータ問題を解決するために、別の組織によって作られました。

この回答に関しては、製品名を間違えたり、レイクハウスの導入に不可欠なものを見落としているものの、比較的正しく理解してくれたことに感心しています。
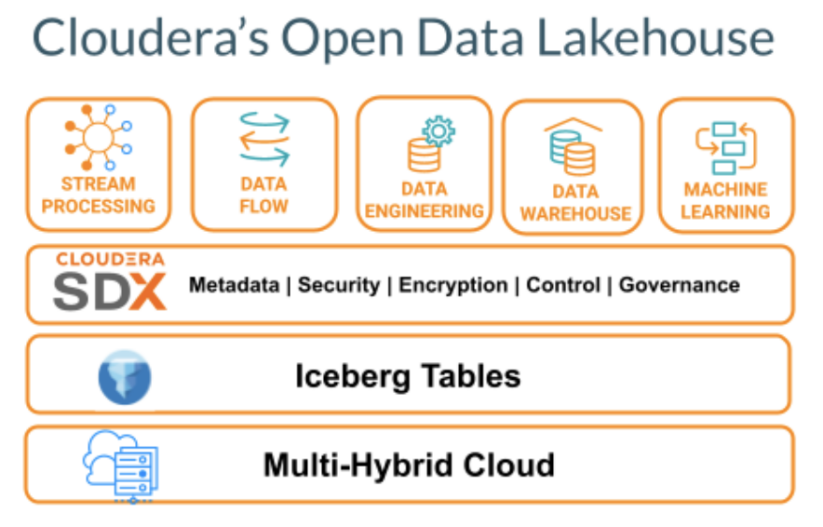
データレイクハウスアーキテクチャを支える CDP のコンポーネントは、以下の通りです。
- CDP に統合されている Apache Iceberg のテーブルフォーマットで、データレイクにある大量の構造化、非構造化データに構造を提供
- CDW と呼ばれるクラウドネイティブデータウェアハウス、CDE と呼ばれるデータエンジニアリングサービス、データ・イン・モーション (移動中のデータ) と呼ばれるデータストリーミングサービス、CMLと呼ばれる機械学習サービスなどを含むデータサービス
- Cloudera の Shared Data Experience (SDX) は、パブリッククラウドとプライベートクラウドの両方で、自動データプロファイラによる統一データカタログ、統一セキュリティ、すべてのデータに対する統一ガバナンスを提供
ChatGPT は新技術を高いレベルで把握するのに最適なツールですが、慎重に使ったほうが良く、また回答に対しては検証が必要です。例えば製品を購入するサイクルで言うと、知見を広める段階で使用することをお勧めします。実際の検討や比較をするのに使用するには、まだ信頼性に欠けます。
ChatGPT の回答は更新され続けるので、このブログが公開される時点では、指摘箇所がすでに修正されているかもしれません。
Cloudera のレイクハウスの詳細については、ウェブサイトをご覧ください。また、ウェビナーやイベントも定期的に開催していますので、ご興味がある方はぜひご確認ください。
