

by Jacob Bengtson, and Peter Ableda
この記事は、2023/05/31に公開された「Generative AI for the Enterprise」の翻訳です。
生成AIの革命の「波」に乗り、ChatGPT や Bard のようなサードパーティの大規模言語モデル (LLM) サービスは急速に人々の間で話題となり、AI に対して懐疑的であった人をエバンジェリストに変え、私たちのテクノロジーとの関わり方をガラリと変えました。ChatGPT がその公開からわずか2ヶ月で1億人のユーザーを獲得し、最も急速に成長したユーザー数の記録を打ち立てたことは、この大きなトレンドの証拠となるでしょう。LLM はほぼすべての業界を変革する可能性を秘めており、私たちはこの新しい生成 AI 時代のスタートラインに立ったに過ぎません。
このような新しいサービスには多くの利点がありますが、万能のソリューションではないことは確かです。これは、自社データを活用した独自のユースケースに生成 AI を採用しようとしている利益を求める企業にとって、特に当てはまることでしょう。生成 AI サービスが企業にもたらすメリットは大きいものの、リスクやデメリットがないわけではありません。
このブログでは、これらの差し迫った問題を掘り下げるとともに、企業に対応した代替手段をご紹介します。これらの懸念に光を当てることで、このような AI モデルを企業で使用する際に生じる限界や課題に対する理解を深め、より責任と信頼性のある AI を活用したソリューションを生み出すために、これらの問題に対処する方法を探ることを目的としています。
生成AIを企業に導入する際の課題
データのプライバシー
データプライバシーはすべての企業にとって重大な関心事です。個人や組織は、そのデータによってもたらされる、急速に進化するデジタルテクノロジーやイノベーションの中で、個人、顧客、企業のデータを保護するという課題に直面しています。
ChatGPT のような SaaS 型の生成 AI アプリケーションは、個人と組織をプライバシーリスクにさらし、情報セキュリティチームの負担を増加させる技術進歩の完璧な例です。サードパーティのアプリケーションは、機密性の高い企業情報を保存・処理する可能性があり、データ侵害や不正アクセスが発生した場合に、その情報が漏洩する可能性があります。サムソンの情報漏洩の件が例として挙げられます。
LLM の文脈の理解の限界
LLM モデルが直面する重大な課題の1つは、特定の企業の質問に対する、文脈の理解の欠如です。GPT-4 や BERT のような LLM は、インターネットで公開されている膨大な量のテキストでトレーニングされており、幅広いトピックと領域を網羅しています。しかし、これらのモデルは、企業のナレッジベースや独自のデータソースにはアクセスできません。その結果、 LLM は企業特有の質問に対して、「ハルシネーション(Hallucination、人工知能の幻覚)」または「事実だが、文脈から外れた回答」という2つの一般的な回答を示すことがあります。
ハルシネーションとは、LLM が現実的な、しかし架空の情報を作り出す傾向のことです。LLM のハルシネーションを見分けるのが難しいのは、そこに事実と虚構が効果的に混在していることです。最近の例では、ChatGPT が提案した架空の法律の引用が、実際の裁判で弁護士によって使用されたことがありました。これを企業の文脈に当てはめると、従業員として会社の出張や転勤の方針について質問した場合、一般的な LLM は合理的だと思われる偽の方針を回答しますが、それは会社が公表しているものとは一致しないということです。
LLM がドメイン固有のクエリに対する具体的な答えについて確信が持てない場合、LLM は文脈に沿わない、一般的な、しかし真実の答えを提供します。例えば、Cloudera Data Warehouse (CDW) の価格について質問した場合、この言語モデルは企業の価格リストや標準的な割引率にアクセスできないため、回答はおそらく CDW と略される衝突損害保険 (Collision Damage Waiver) の一般的な料金を提供することになります。その回答は、確かに事実に基づきますが、Cloudera の文脈からは外れてしまいます。
このような課題に企業が対応する方法とは?
企業がホストする LLM でデータプライバシーを確保する
データプライバシーを確保する1つの選択肢は、企業が開発し、ホストする LLMアプリケーションを使用することです。LLM をゼロからトレーニングするのは魅力的に見えるかもしれませんが、莫大なコストがかかります。OpenAIの CEO である Sam Altman は、GPT-4 のトレーニングにかかる費用を1億ドル以上と見積もっています。
嬉しいニュースとしては、オープンソースコミュニティが無敗を保っていることです。様々な研究チームや組織によって開発された新しい LLM が毎日 Hugging Face 上でリリースされています。これらは最先端の技術やアーキテクチャに基づいて構築され、より広い AI コミュニティの集合的な専門知識が活用されています。Hugging Face はまた、これらの事前に訓練されたオープンソースモデルへのアクセスを容易にしており、会社はより有利な出発点から LLM の取り組みを始めることができます。さらに、新しく強力なオープン代替モデル (MosaicMLのMPT-7B、Vicuna等) が急速なペースで提供され続けています。
オープンソースモデルは、企業が研究、インフラ、開発に莫大な費用をかけることなく、企業内で AI ソリューションをホストすることを可能にします。これはまた、これらのモデルとのインタラクションが社内で保持されることを意味し、ChatGPT や Bard のような SaaS 型の LLM ソリューションに関連するプライバシーの懸念を解決します。
LLMへの企業独自の文脈の追加
文脈の制限は企業特有のものではありません。OpenAI のような SaaS 型 LLM サービスには、顧客のデータをサービスに統合する有料サービスがありますが、これには非常に明白なプライバシーへの影響があります。上記の AI コミュニティもこのギャップを認識しており、すでに様々なソリューションを提供しています。これにより、データを外部に公開することなく、自社ホストの LLM に文脈を追加することが可能です
Ray や LangChain のようなオープンソースのテクノロジーを活用することで、開発者は企業固有のデータを使って言語モデルを微調整することができます。これにより、タスク固有の理解を促進し、希望するトーンを維持することで、レスポンスの品質が向上します。結果として、モデルは顧客からの問い合わせを理解し、より良い回答を提供し、顧客固有の言語のニュアンスに巧みに対応することが可能になります。微調整は、LLM に企業の文脈を追加するのに有効です。
文脈の制限に対するもう一つの強力な解決策は、検索拡張生成 (RAG) のようなアーキテクチャの使用です。このアプローチは、Milvus のようなベクターデータベースにドキュメントを格納し、ナレッジベースから情報を取得する機能と、生成機能を組み合わせたものです。ナレッジベースを統合することで、LLM は生成プロセス中に特定の情報にアクセスすることができます。この統合により、モデルは言語ベースだけでなく、独自のナレッジベースの文脈に基づいた回答を生成することができます。
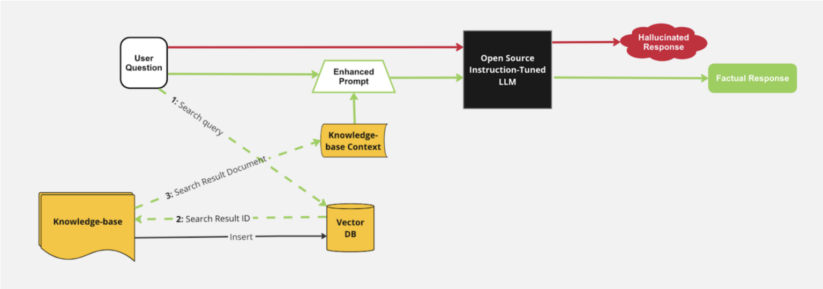
LLM プロンプトへのナレッジ文脈格納のための RAG アーキテクチャ図
これらのオープンソースのスーパーパワーにより、企業は、一般化された、「何でも得意なLLM」ではなく、特定のユースケースを得意とするように調整された特定領域の専門家としての LLM を作成し、ホストすることができます。
Cloudera:企業向け生成AIを実現
もし、生成AIという新しい挑戦が難しいと感じても、ご安心ください。Cloudera がこの取り組みのガイドをいたします。当社は複数の独自の優位点があります。それは、お客様の専有データ、または規制対象データを使用して、それらが流出するリスクを排除しながら、LLM から最大の価値を引き出すための完璧なパートナーとして位置付けられています。
Cloudera は、パブリッククラウドとプライベートクラウドの両方でオープンデータレイクハウスを提供する唯一の企業です。私たちは、エッジからAIまで、データライフサイクル全般にわたる開発を可能にする、目的に応じたデータサービス群を提供します。リアルタイムのデータストリーミング、オープンレイクハウスでのデータの保存と分析、機械学習モデルのデプロイと監視など、Cloudera Data Platform (CDP) はお客様のあらゆるニーズに対応します。
Cloudera Machine Learning (CML) は、CDP で提供されるこれらのデータサービスの1つです。CML を利用することで、企業は選択したオープンソースの LLM を搭載した独自の AI アプリケーションを、自社のデータで構築することができます。このサービスにより、データサイエンティストや ML チームだけでなく、すべての開発者や事業部門が力を発揮することで、AI を真に民主化することが可能になります。
今こそ始める時です
このブログの冒頭で、生成 AI を「波」と表現しましたが、実際のところ、それは津波のようなものです。企業が今後も競争力を保つためには、今日からこの技術の実験を始めて、近い将来に向けて実用化の準備を始める必要があります。そのために、私たちは AI と LLM の実験を加速させる、新しい Applied ML Prototype (AMP) のリリースを発表します。「LLM Chatbot Augmented with Enterprise Data」は、企業向けの生成 AI を実現するためのオープンソースライブラリや技術の活用方法を実証する AMP シリーズの第1弾です。
この AMP は、このブログで取り上げた RAG ソリューションのデモンストレーションです。コードは100%オープンソースであるため、誰でも利用することができます。Cloudera のすべてのお客様は CML ワークスペースから、ワンクリックでデプロイすることが可能です。