

by Christopher Van Dyke
この記事は、2023/4/27に公開された「Running Ray in Cloudera Machine Learning to Power Compute-Hungry LLMs」の翻訳です。
OpenAI についての話題で忘れられがちなのは、GPTのような大規模言語モデル (LLM) や ChatGPT のような生成 AI の訓練と微調整に必要な膨大な計算処理です。各イテレーションはより多くの計算を必要とします。ムーアの法則によって課された制限により、そのタスクは単一インスタンス環境から分散処理 (分散コンピューティング) へと課題を急速に移行させます。これを実現するため、OpenAI は Ray を使用して、リリースする各 GPT モデルを訓練する分散処理プラットフォームを強化しています。Ray は、AI ワークロードの分散処理においてApache Sparkよりも優れたパフォーマンスを発揮するため、人気のフレームワークとして浮上しています。このブログでは、Ray を Cloudera Machine Learning のオープン・バイ・デザイン・アーキテクチャにおいてどのように使用し、CDP に高速な分散 AI コンピューティングをもたらすことができるかを説明します。これは、公開された python パッケージ、Ray Module in cmlextensionsによって可能になります。
シンプルで効率的な分散コンピューティング機能を提供する Ray の能力は、Python のネイティブサポートとともに、データサイエンティストやエンジニアの間で人気となっています。その革新的なアーキテクチャは、TensorFlow や PyTorch のような機械学習 (ML) や深層学習 (DL) ライブラリとのシームレスな統合を可能にします。さらに、きめ細かなタスクスケジューリングに重点を置いた Ray の並列処理に対する独自のアプローチにより、Spark に比べてより幅広いワークロードに対応できます。このような柔軟性の向上と使いやすさにより、Ray は分散コンピューティングのパワーを活用しようとする組織にとって最適な選択肢となっています。
Kubernetes 上に構築されたCloudera Machine Learning (CML) は、データサイエンスチームに機械学習ライフサイクルの各段階にわたって機能するプラットフォームを提供し、探索的データ分析、モデル開発、そして「MLOps」と呼ばれるモデルやアプリケーションの本番環境への移行をサポートします。CML はオープン志向に基づいた設計 (オープン・バイ・デザイン) をベースに構築されており、そのため複数のコンピュートポッドをオンデマンドで迅速にスピンアップできる Worker API が含まれています。Cloudera のお客様は、CML の大規模なコンピュートクラスタをスピンアップする機能を Ray と統合することで、Python ネイティブの使いやすい分散コンピューティングプラットフォームを実現することができます。Ray は、強化学習、ハイパーパラメータチューニング、モデルのトレーニングやサービングのための独自のライブラリを提供しますが、ユーザーはXGBoost、Pytorch、LightGBM、Dask、Pandas (Modinを使用) などのお気に入りのパッケージを持ち込むこともできます。これは CML のオープン・バイ・デザインに合致し、データサイエンティストはオープンソースコミュニティから最新のイノベーションを利用することができます。
CML ユーザーが Ray を活用しやすくするために、Cloudera は CMLextensions と呼ばれる Python パッケージを公開しています。CMLextensions には Ray モジュールがあり、CML のコンピュートワーカーのプロビジョニングを管理し、Ray クラスタをユーザに返します。
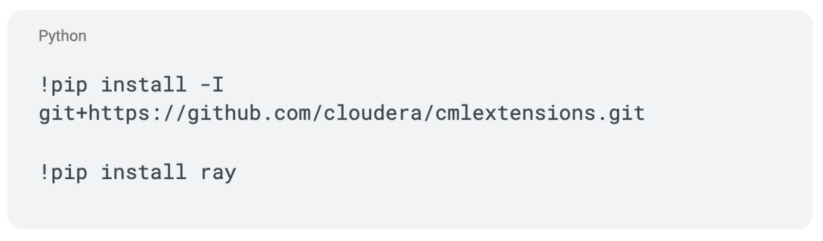
CML で Ray を始めるには、まず CMLextensions ライブラリをインストールする必要があります。
これで Ray クラスタをスピンアップすることができます。

これでプロビジョニングされたRayクラスタが返されます。

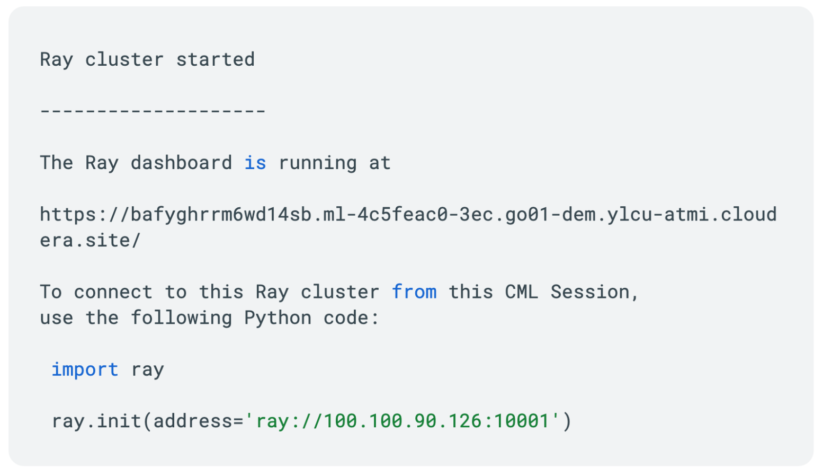
これで Ray クラスタのプロビジョニングが完了し、作業を開始する準備ができました。以下のコードで Ray クラスタをテストすることができます:


最後に、Rayクラスタを使い終わったら、終了させます:

Ray は高速且つ分散した Python アプリケーションを構築するハードルを低くします。これで Cloudera Machine Learning で Ray クラスタをスピンアップすることができます。Ray を使用して Python コードをどのように並列化および分散できるか確認してみましょう。これを最もよく理解するために、Ray タスクとアクター、および Ray API を使用して分散処理を実装する方法について見ていく必要があります。
まず、既存の関数を Ray タスクにする概念を見ていきます。数の2乗を求める簡単な関数を見てみましょう。


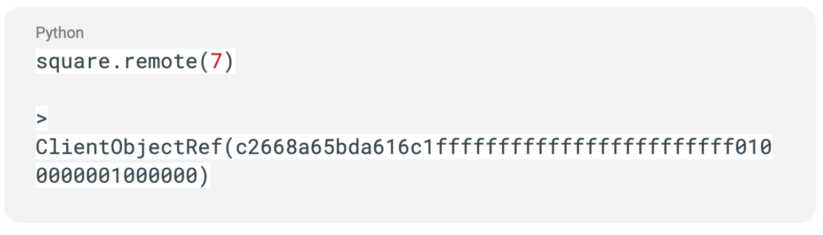
これをリモート関数にするには、@ray.remote デコレーターを使用するだけです。

これにより関数はリモート関数となり、関数を呼び出すとすぐにオブジェクト参照を持つ future が返されます。
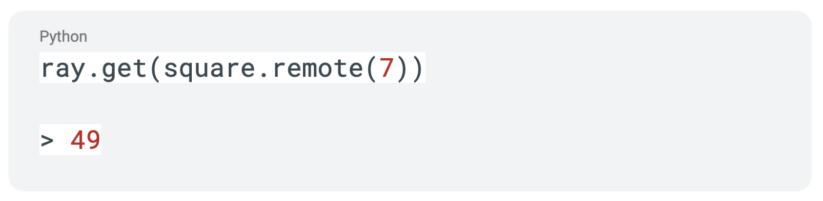
関数呼び出しの結果を取得するために、関数と一緒に ray.get API 呼び出しを使用することができ、呼び出しの結果が返されるまで実行がブロックされます。
Ray タスクの次は、Ray アクターの概念について説明します。アクターは、ワーカーノード上で実行されるリモートクラスだと考えてください。テストの得点を追跡する簡単なクラスから始めましょう。同じ @ray.remote デコレータを使って、このクラスを Ray アクターに変えます。

次に、このアクターのインスタンスを作成します。

このアクターをデプロイすると、Ray Dashboard でインスタンスを見ることができます。
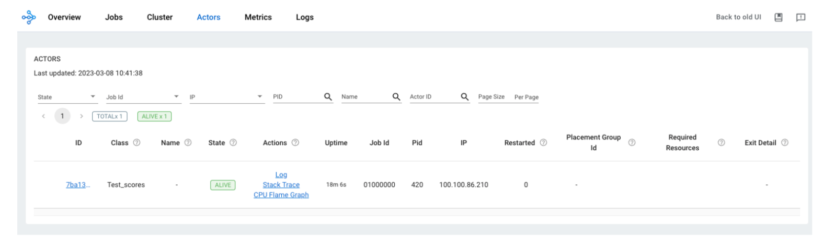
Ray タスクと同様に、「.remote」エクステンションを使って Ray アクター内で関数を呼び出します。

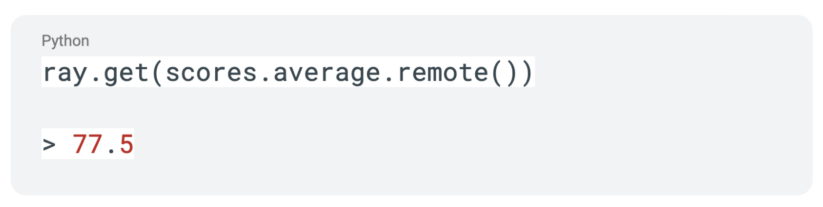
Ray タスクと同様に、Ray アクターへの呼び出しはオブジェクト参照のみが返されます。同じく ray.get API 呼び出しを使用して、データが返されるまで実行をブロックすることができます。
アクターへの呼び出しは、Ray Dashboard でも追跡可能になります。下にアクターが表示され、そのアクターへのすべての呼び出しを追跡でき、そのワーカーのログにアクセスできます。
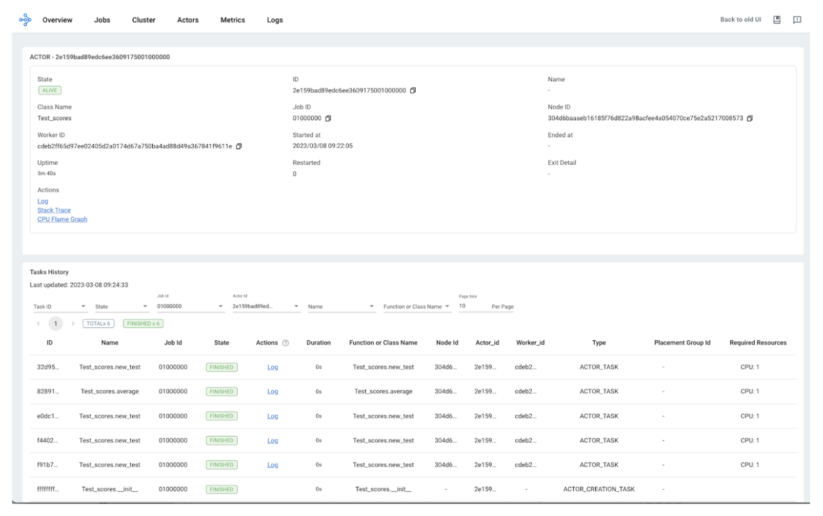
アクターのライフタイムは、現在のジョブから切り離すことができます。ray.remote デコレータを通して、アクターのリソース要件を指定できます。

今回は Ray のタスクとアクターの概念について簡単に説明しました。ここでは表面をなぞっただけですが、Ray をより深く理解するための良い基礎になると思います。Ray がどのようにデータフレームのワークロードを分散し、高速化する基盤になるかも後にご紹介したいと思います。
あらゆる規模や業種の企業が、様々なドメイン固有のアプリケーションをパワーアップできる LLM を試行錯誤し、イノベーションを活用しています。Cloudera のお客様は、Ray のような次世代の分散コンピューティングフレームワークをデータ上で活用いただけます。これこそ、オープン・バイ・デザインの力です。
Cloudera Machine Learning の詳細については、ウェブサイトをご覧ください。CML でRayを使い始めるには、Github の CMLextensions をご覧ください。
