

by George Vetticaden
この記事は、2022/06/02に公開された「Moving Enterprise Data From Anywhere to Any System Made Easy」の翻訳です。
2015年以来、Cloudera DataFlow チームは、世界最大の企業組織が企業標準のデータ移行ツールとして Apache NiFi を採用することを支援してきました。ここ数年、私たちは、エッジ、オンプレミス、複数のクラウドプロバイダにわたってデータ資産を拡張するお客様のハイブリッドクラウドへの道のりを、最前列で見てきました。そんなハイブリッドクラウドの採用を進めるお客様のデータ移行を支援するという立場から、Clouderaは、最新のハイブリッドデータスタックを採用する際に出てくる重要な要件を、明確に把握することができました。
明らかになった重要な要件の1つは、オンプレミスとクラウドの両方で、データの起点からすべての消費ポイントまでのデータフローを、シンプルで安全、普遍的、拡張可能、かつコスト効率の高い方法で制御することを求める企業のニーズの高さです。このようなニーズから、ユニバーサルデータ配信サービスの市場機会を見出しました。
過去2年間、Cloudera DataFlow チームは、Cloudera DataFlow for the Public Cloud (CDF-PC) の構築に尽力してきました。CDF-PC は、Kubernetes 上のApache NiFi を利用したクラウドネイティブのユニバーサルデータ配信サービスで、開発者は任意の構造の任意のデータソースに接続し、それを処理し、任意の宛先に配信できるようにします。
今回のブログ記事では、以下の2点に触れたいと思います。
- ユニバーサルデータ配信サービスとは何か?
- 最新のデータスタックを使用する際に、なぜすべての組織が、ユニバーサルデータ配信サービスを必要とするのか?
最近、ある大手小売業向けデータサイエンスメディアのお客様向けワークショップで、参加者の一人であるエンジニアのリーダーが次のようなことを語りました。
「Cloudera の競合会社のウェブサイトを見ると、その会社のシステムにどうやってデータを取り込むのか、などのように、自らの製品の情報ばかりです。正直私は、そのシステムに興味があるというより、すべてのシステム間の統合を望んでいます。それぞれのシステムは、使用している多数のシステムの1つに過ぎないのです。だからこそ、Cloudera が NiFi を使い、すべてのシステム間を統合していることが気に入っています。コミュニティに配慮した考えを持つツールの1つであり、そんな製品を提供してくれて本当に感謝しています。」
Cloudera DataFlow チームが関わってきた多くの企業、特にクラウドで最新のデータスタックを採用しているお客様からは、同様の感想が多く寄せられています。
そもそも、最新のデータスタックとは何でしょうか?人気のあるブログやLinkedIn への投稿では、次のように説明されています。

最新のデータスタックについてのこの図について、いくつかの見解を述べたいと思います。
- 異なるボックスがいくつもあることに注目してください。最新のデータスタックでは、データを配信すべき先が多様に存在し、これは課題と挑戦を伴うことを意味します。
- 最新の「抽出/ロード」ツールは、主にスキーマを持つクラウドデータソースを対象としているようです。しかし、Cloudera のお客様である2,000社以上の企業によると、ソースとなり得るデータの半分以上は、クラウドの外(オンプレミス、エッジなど)で生まれ、必ずしもスキーマを持っていません。
- クラウドサービスのエコシステム間でデータを移行させるには、数多くの「抽出/ロード」ツールを使用する必要があります。
これらの点について、さらに掘り下げていきます。
残念ながら、企業は、データの収集と配信を重要な課題として扱ってきませんでした
過去10年間、ヘテロジニアスな環境(クラウド、オンプレ、エッジ)におけるデータ作成ソース(モバイルアプリケーション、ラップトップ、センサー、エンタープライズアプリケーション)の急増により、作成されるデータが指数関数的に増加していることをよく耳にします。同時に、データを配信する必要のあるクラウドサービスも急速に増えています(データレイク、レイクハウス、クラウドウェアハウス、クラウドストリーミングシステム、クラウドビジネスプロセスなど)。ユースケースでは、もはやデータをデータウェアハウスやデータソースの一部だけに配信するのではなく、クラウドプロバイダーやオンプレミスにまたがる多様なハイブリッドサービスに配信することが求められています。
企業はこれまで、データ資産全体におけるデータの収集、配信、追跡を、一流のソリューションを必要とする重要な問題として扱ってきませんでした。その代わりに、ソースと宛先に限定したデータ収集のためのツールを構築、または購入していました。前述の通り、ソースシステムは決してクラウド構造化されたソースだけに限定されないということを考慮すると、問題はさらに次の図のように複雑化します。
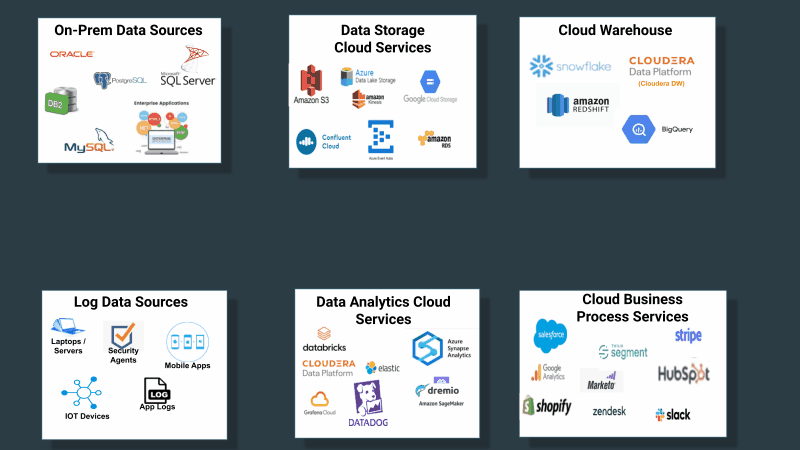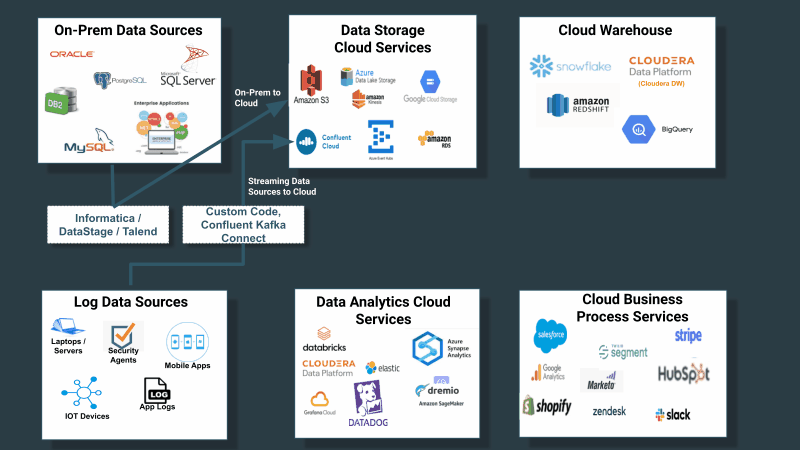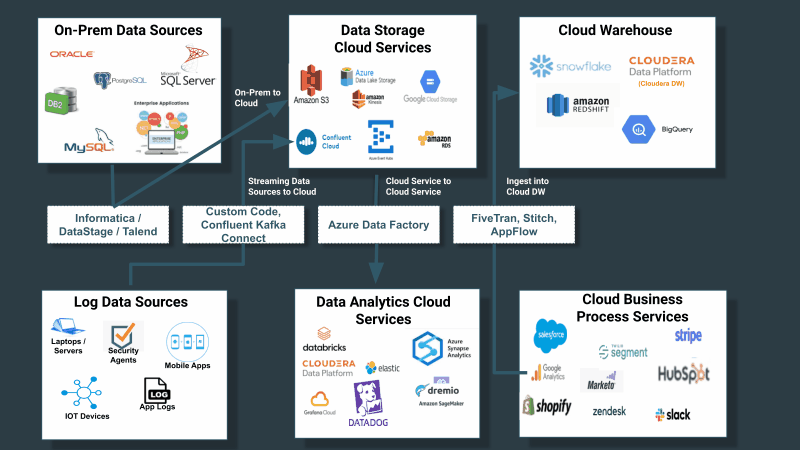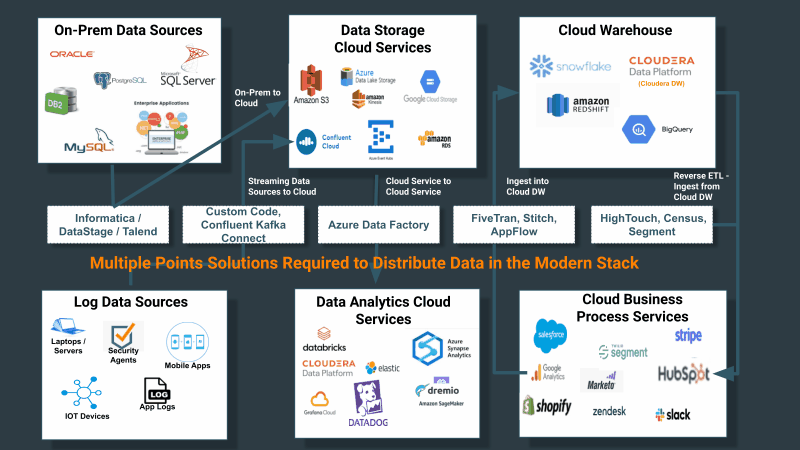
ユニバーサルデータ配信サービスの必要性
クラウドサービスの普及が進むにつれ、複数のポイントソリューションを利用するという現在のアプローチは困難になってきています。
そんな例として、ある大手石油・ガス会社では、10万台を超えるエッジデバイスのストリーミングサイバーログを、Splunk、Microsoft Sentinel、Snowflake、データレイクなど複数のクラウドサービスに移行する必要がありました。
「データの配信を制御することは、データをさまざまなサービスに配信するための自由度と柔軟性を提供する上で非常に重要です。」
ハイブリッドクラウドの実現に取り組む組織は、データの流れを起点からすべての消費ポイントまで制御する能力が必要です。本ブログの冒頭で述べたように、このニーズがデータ配信サービスに対する市場機会を生み出しました。

データ配信サービスが備えるべき重要な機能とは?
- ユニバーサルデータ接続とアプリケーションへのアクセス性:言い換えれば、ハイブリッドな世界での取り込みをサポートし、あらゆるクラウドのあらゆるデータソースに、あらゆる構造で接続できるサービスであることが必要だということです。ハイブリッドとは、クラウドの外で生まれたあらゆるデータソースからの取り込みをサポートし、これらのアプリケーションから配信サービスに簡単にデータを送信できるようにすることも意味します。
- ユニバーサルで相手を選ばないデータデリバリ:データレイク、レイクハウス、データメッシュ、クラウドサービスなど、あらゆる宛先への配信をサポートするサービスです。
- ストリーミングを第一級オブジェクトとしたユニバーサルなデータ移行のユースケース:継続的/ストリーミング、バッチ、イベントドリブン、エッジ、マイクロサービスなど、多様なデータムーブメントのユースケースに対応する必要があります。このようなユースケースの中で、ストリーミングは第一級オブジェクトとして扱われ、あらゆるデータソースをストリーミングモードに変換し、何十万ものデータ生成クライアントを強化するストリーミングスケールをサポートできるサービスである必要があります。
- ユニバーサルな開発者のアクセシビリティ:データ配信は、データ統合の問題であり、それに伴うすべての複雑な問題です。コネクタウィザードベースのおぼつかないソリューションでは、一般的なデータ統合の課題(ブリッジプロトコル、データフォーマット、ルーティング、フィルタリング、エラー処理、再試行など)に対応できません。同時に、開発者は、データ配信パイプラインを構築するための拡張性のあるローコードツールを求めています。
Cloudera DataFlow for the Public Cloud は、Apache NiFi を利用したユニバーサルデータ配信サービスです
Cloudera DataFlow for the Public Cloud (CDF-PC) は、Apache NiFi によるクラウドネイティブのユニバーサルデータ配信サービスで、データの収集と配信の問題を解決するために、接続性とアプリケーションのアクセス性、ユニバーサルなデータ配信、第一級オブジェクトとしてのストリーミングデータパイプライン、および開発者のアクセス性の4つの主要機能で構築されています。
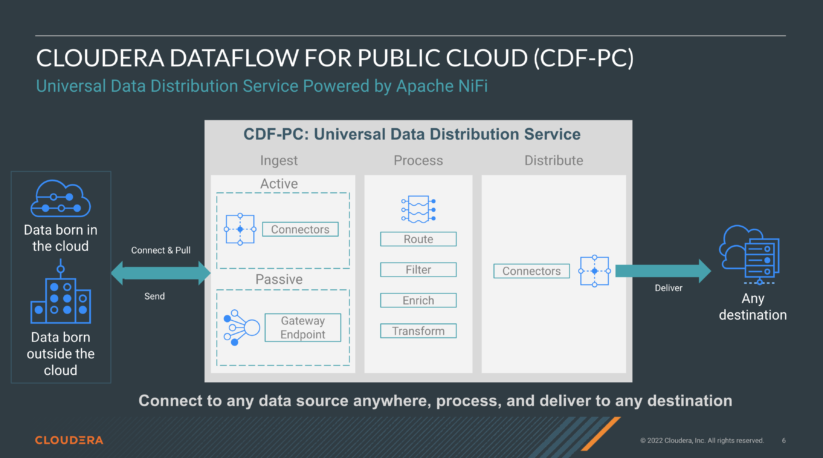
CDF-PC は、開発者がデータ配信パイプラインを設計、開発、テストする方法に最も適したフローベースのローコード開発パラダイムを提供します。データレイク、レイクハウス、クラウドウェアハウス、クラウド外のソース等、ハイブリッドクラウドサービスのエコシステムにまたがる400以上のコネクタとプロセッサにより、CDF-PC はユニバーサルなデータ配信を提供します。これらのデータ配信フローはカタログでバージョン管理され,オペレータはクラウドプロバイダのKubernetes サービスやファンクションサービス(FaaS)を含む、さまざまなランタイムにセルフサービスで配備することができます。
組織は CDF-PC を、何十万ものエッジデバイスからのストリーミングデータ収集によるサイバーセキュリティ分析や SIEM 最適化から、セルフサービス分析ワークスペースのプロビジョニングやレイクハウス(例:Databricks、Dremio)へのデータのハイドレーション、クラウドオブジェクトストレージ(AWS、Azure,Google Cloud)やクラウドウェアハウス(Snowflake、Redshift、Google BigQuery)でバックアップされたクラウドプロバイダのデータレイクへのデータ取り込みに至る、さまざまなデータ配信ユースケースで利用しています。
今日から始める
ハイブリッドクラウドの取り組みのどのステージにいたとしても、最新のハイブリッドデータスタックをうまく採用するためには、第一級のデータ配信サービスが不可欠です。Cloudera DataFlow for the Public Cloud (CDF-PC) は、ユニバーサル、ハイブリッド、ストリーミングファーストのデータ配信サービスを提供し、お客様がデータフローを制御することを可能にします。
ぜひ、インタラクティブな製品ツアーで CDF-PC の使用感を体験いただく、もしくは、無償トライアルにご登録ください。
