

この記事は、2022/3/23に公開された「5 Reasons to Use Apache Iceberg on Cloudera Data Platform (CDP)」の翻訳です。
Apache Icebergとは?
Apache Icebergは、基盤となるストレージレイヤーやデータアクセスレイヤーに依存せず、ペタバイト級まで拡張可能なクラウド生まれの高性能でオープンなテーブルフォーマットです。
Apache Icebergは真にオープンなテーブルフォーマットであるため、Cloudera Data Platform (CDP) のビジョンと合致します。最近、Clouderaは弊社のクラウドエコシステムとの統合を発表しました。これにより、企業はパブリッククラウドへの移行や、Lakehouseのような統合型アーキテクチャの採用に際して、Icebergのメリットを活用できるようになります。
今回のブログ記事では、そのメリットと、CDPとIcebergを選択することで、どのように次世代データアーキテクチャを将来にわたり支えることができるのかをご紹介いたします。
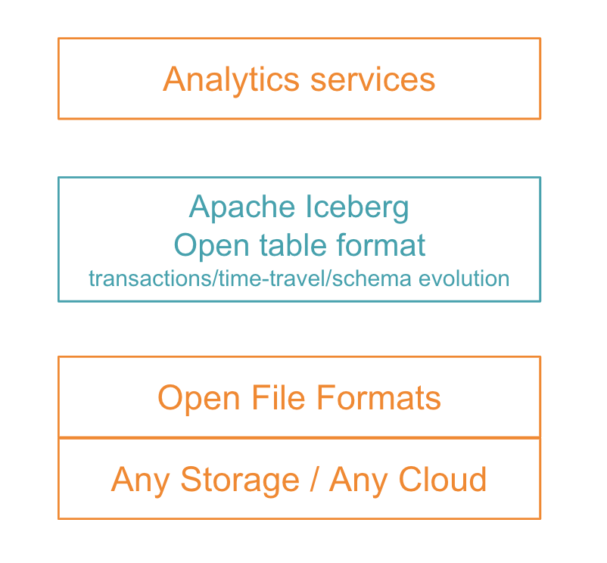
図1:Apache Icebergは、タイムトラベルやパーティションの進化といった新しい機能を導入しながら、ストレージ層と分析層を抽象化し、次世代データアーキテクチャに適合します。
1. 多機能分析
Apache Icebergは、異なるストリーミングエンジンや処理エンジン間でデータの整合性を保ちながら、シームレスな統合を可能にします。複数のエンジンが同時にテーブルを変更することができ、部分的な書き込みがあっても、正確性の問題はなく、パフォーマンスに影響が大きなREAD LOCKは必要ありません。したがって、Icebergを使えば、データセットを扱うために、異なるコネクタや、異質でメンテナンスが不十分なAPI、その他のユースケース特有の回避策を使用する必要性を軽減します。
Icebergは、データセットを共有できるように、オープンでエンジンに依存しない設計になっています。Clouderaは、HiveとImpalaのサポートを拡大し、大規模データエンジニアリング(DE)ワークロードやストリーム処理(DF)から高速なBIやクエリ(DW内)、機械学習(ML)まで、多機能分析のためのデータアーキテクチャというビジョンを実現しました。
多機能であることは、統合されたエンドツーエンドのデータパイプラインを意味し、サイロをなくし、分析を一貫したライフサイクルとしてまとめ、各段階においてビジネス価値を引き出すことができるようにすることです。ユーザーは、自分の好みのツールを選び、そのワークロードに特化した最適化を利用できるようにする必要があります。例えば、CMLのJupyterノートブックでは、SparkやPythonフレームワークを使用してIcebergテーブルに直接アクセスして予測モデルを構築し、NiFiフローで新しいデータを取り込み、SQLアナリストはCDP Data Visualizationで収益目標を監視する、ということが可能です。また、Icebergは完全なオープンソースプロジェクトであるため、今後さらに多くのエンジンやツールがサポートされることになります。
2. オープンフォーマット
Icebergは、テーブルフォーマットとして、最も一般的に使用されているオープンソースファイル形式であるAvro、ParquetおよびORCをサポートしています。これらのフォーマットは、オープンソースコミュニティで使用されているだけでなく、サードパーティツールにも組み込まれており、知名度もある成熟したフォーマットです。
オープンフォーマットの価値は、柔軟性とポータビリティです。ユーザーは、基盤となるストレージに縛られることなく、ワークロードを移動させることができます。しかしこれまでは、しかしこれまでのテーブルフォーマットは、一部が欠けていました。テーブルスキーマとストレージの最適化は、エンジンも含めて密結合になってしまうケースが多かったのです。
一方、Icebergはオープンなテーブルフォーマットで、この密結合を避けるためにオープンなファイルフォーマットに基づいています。テーブル情報(スキーマ、パーティションなど)はメタデータ(マニフェスト)ファイルの一部として別途保存されるため、アプリケーションはテーブルと好みのストレージ形式を迅速に統合することが容易になります。また、クエリがテーブルの物理レイアウトに依存しなくなったため、Icebergのテーブルはデータ量の変化に応じてパーティションスキームを進化させることができます(この点は、ブログ後半で詳しく説明いたします)。
3. オープンパフォーマンス
オープンソースは、ベンダーロックインを避けるために重要ですが、多くのベンダーは、自社ツールとオープンソースコミュニティの間のギャップを認識しつつも、オープンソースツールを売り込んでいます。つまり、オープンソースバージョンに移行しようとすると、大きな違いがあり、結果としてベンダーロックインを回避することができないのです。
Apache Icebergプロジェクトは、さまざまな処理エンジンのサポートを急速に拡大し、新しい機能を追加している活気あるコミュニティです。これは、新しいテーブルフォーマットの継続的な成功に不可欠であると考えており、だからこそ、Spark、Hive、Impalaのアップストリームコミュニティへの貢献に取り組んでいるのです。コミュニティの成功があることで、Apache Icebergを採用し、次世代のデータアーキテクチャを構築しようとしている企業に届けることができるのです。
コミュニティはすでに、Vectorization readsやZ-Orderなど、多くのパフォーマンス改善と機能エンハンスメントを提供しており、テーブルにアクセスするエンジンやベンダーに関係なく、ユーザーに利益をもたらします。CDPでは、Impala MPPオープンソースエンジンのZ-Orderのサポートの一部として、すでに利用可能です。
Icebergは、すでに述べた通りクエリプランニングにおいて、メタデータファイルに基づいており、データの保存場所やパーティショニング、スキーマがどのようにファイル間で広がっているかが記載されています。これによってスキーマの進化が可能になりますが、テーブルにあまりに多くの変更があった場合には、問題が生じます。そのため、コミュニティではマニフェスト(メタデータ)ファイルを並列に読み込むAPIを作成し、他にも同様の最適化に取り組んでいます。
このオープンスタンダードのアプローチにより、ベンダーロックインを心配することなく、CDPのパフォーマンスでIceberg上のワークロードを実行することができます。
4. エンタープライズグレード
Clouderaエンタープライズプラットフォームの一部として、Icebergのネイティブ統合は、データリネージ、監査、セキュリティといったShared Data Experience(SDX)のエンタープライズグレードの機能を、再設計やサードパーティツールの統合なしに利用することができます。サードパーティツールがいらないということは、管理の複雑化や追加の知識の習得を必要としないということです。
CDPのApache Icebergテーブルは、テーブル構造とアクセスの検証のためにSDXメタストア内に統合されています。これは、監査ときめ細かいポリシーの作成がすぐにできることを意味します。
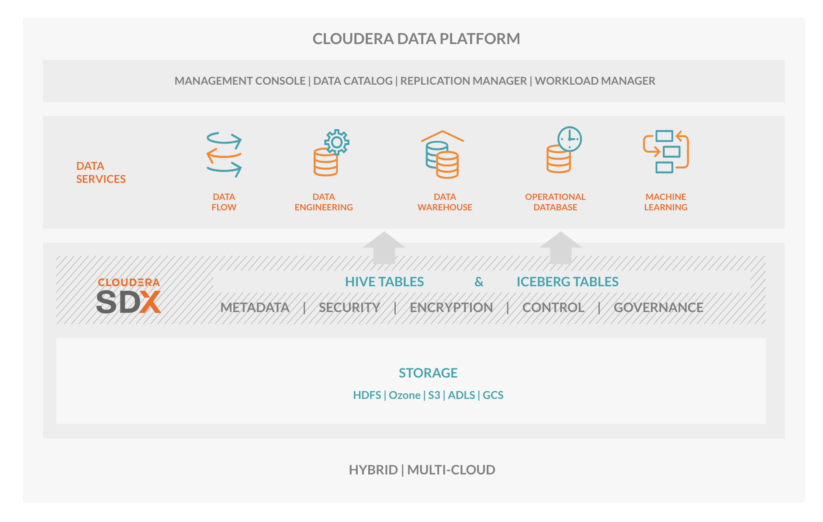
図2:Cloudera Data Platform内のApache Iceberg
5. 新しいユースケースへの扉を開く
Apache Hiveテーブルは、データウェアハウス、データエンジニアリング、機械学習へのテーブルアクセスを一元化することで、優れた基礎を築きました。また、オープンなファイル形式(ORC、AVRO、Parquetなど)をサポートし、ACIDとトランザクションのサポートにより新しいユースケースを実現するのに貢献しました。しかし、メタデータの一元化や、主にファイルベースの抽象化により、スケールなどの特定の領域で苦戦を強いられてきました。
Icebergは、規模とパフォーマンスの課題を克服すると同時に、一連の新機能を導入しています。これらの新機能が、さまざまな業界やユースケースにおける課題にどのように取り組むことができるのか、簡単にご説明します。
変更データキャプチャ(CDC)
Hive ACIDのような既存のソリューションでは、すでに差分を原子性と一貫性をもって処理することができ、新しい要素ではありませんが、DWやBIのユースケースに供給するデータ処理パイプラインの多くでは、差分を処理する能力は重要です。そのためIcebergは、行レベルの更新と削除をサポートすることで、初めからこの問題に取り組んでいます。詳細は省きますが、これを実現するには、例えばコピーオンライトやマージオンリードなど、さまざまな方法があることは知っておく価値があります。しかし、より重要なのは、これらの実装とIcebergオープンスタンダード形式の継続的な進化(バージョン1の仕様とバージョン2の仕様)を通じて、このユースケースのパフォーマンスが向上することです。
金融規制
多くの金融業界や規制の厳しい業界では、テーブルを特定の時点まで振り返り、復元する方法を求めています。Apache Icebergのスナップショットとタイムトラベル機能を使えば、アナリストや監査役がSQLのようなシンプルさで簡単に過去にさかのぼってデータを分析できるようになります。
ML Opsの再現性
Icebergでは、過去のテーブルの状態を取得できるため、MLエンジニアは元の状態のデータでモデルを再トレーニングしたり、予測値を過去のデータにマッチングさせる事後分析を行ったりすることができます。このような過去のフィーチャーストアを介して、モデルを再評価し、欠陥を特定し、より新しい、より良いモデルを展開することができます。
データ管理の簡略化
データを扱う人の多くは、データ管理の複雑さに対処するために多くの時間を費やしています。例えば、プロジェクトで新しいデータソースが確認され、その結果、既存のデータモデルに新しい属性を導入する必要があるとします。今までは、特に新しいパーティションを導入する場合、テーブルの再作成と再読み込みに長い開発サイクルを要することがありました。しかし、Iceberg のテーブルとそのメタデータマニフェストファイルを使用すれば、追加コストをかけずに更新を合理化することができます。
- スキーマの進化:テーブルのカラムは、データの可用性に影響を与えることなく、その場で変更(追加、削除、名前の変更、更新、並び替え)することが可能です。すべての変更はメタデータファイルで追跡され、Icebergはスキーマの変更が独立しており、副作用(不正確な値など)がないことを保証します。
- パーティションの進化:Icebergテーブルのパーティションは、進化するスキーマと同じように変更することができます。パーティションを進化させる場合、古いデータは変更されず、新しいデータは新しいパーティション仕様に従って書き込まれます。Icebergは非表示のパーティショニングを使用して、一致するデータを含むファイルを分割計画によって古いパーティション仕様と新しいパーティション仕様から自動的に取り除きます。
- 粒度の細かいパーティショニング:従来、メタストアとクエリプランニング時のパーティションメモリへのロードが大きなボトルネックとなり、テーブルのサイズが大きくなるにつれてパフォーマンスの低下を懸念するユーザーが、時間単位のパーティションスキームを使用することを妨げていました。Icebergは、メタストアとメモリのボトルネックを完全に回避することで、こうしたスケーラビリティの課題を克服し、アプリケーションの要件に最も適したより詳細なパーティションスキームを使用することで、より高速なクエリを可能にします。
つまり、データ実務者は、ビジネス価値の提供や新しいデータアプリケーションの開発により多くの時間を費やし、データ管理業務に費やす時間を減らすことができるのです。
ビジネスのスピードに合わせてデータを進化させる。その逆はありません。
「あらゆる」ハウス
データウェアハウスの分野では、さまざまなトレンドが見られますが、最新のトレンドの1つが、データウェアハウスとデータレイクを組み合わせた統合アーキテクチャを指す「Lakehouse」です。 企業におけるこのような統合アーキテクチャの主な促進要因は、ストレージと処理エンジンの分離にあります。しかし、これには、ストリーム分析やリアルタイム分析からウェアハウスや機械学習まで、多機能な分析サービスを組み合わせる必要があります。単一の分析ワークロード、あるいは2つの組み合わせでは十分ではありません。そのため、CDPの中のIcebergはアナモフィック、つまりエンジンにとらわれない、クラウドスケーラブルなオープンデータ基盤なのです。
これにより、最適なパフォーマンスを得るために独自のストレージ形式や、1つのエンジンやサービスにおける独自の最適化に頼ることなく、「あらゆる」ハウスを構築することが可能になります。
Icebergは、データを迅速かつ安定的に提供する分析テーブルレイヤーで、問題もなく、あらゆる機能を備えています。
まとめ
CDPとIcebergを選択することで、次世代のデータアーキテクチャを将来的にも保証できる5つの理由を簡単にまとめます。
- ストリーミング、データキュレーション、SQLアナリティクス、機械学習などのユースケースに最適なエンジンを選択することができる
- フレキシブルでオープンなファイルフォーマット
- パフォーマンスを含め、アップストリームコミュニティのすべてのメリットを得ることができ、ベンダーロックインを心配する必要がない
- エンタープライズグレードのセキュリティとデータガバナンス:データの認証・認可からリネージ、監査までを一元化
- 新しいユースケースへの実現につながる
すべてを網羅したわけではありませんが、Apache Icebergが、クラウドネイティブアプリケーションのための次世代テーブルフォーマットとして認識されている理由をご説明いたしました。
IcebergをCDPで試してみませんか?ご希望の方は、Clouderaのアカウント担当者にお問い合わせください。また、Clouderaが初めての方は、60日間のトライアルがございますので、お試しください。
