

この記事は、2024/2/8 に公開された「Accelerating Queries on Iceberg Tables with Materialized Views」の翻訳です。
概要
このブログポストでは、Cloudera Data Warehouse における Iceberg テーブルフォーマットのマテリアライズド・ビューのサポートについて説明します。
Apache Iceberg はペタバイトスケールの分析データセットのための高性能なオープンテーブルフォーマットです。言語や実装を超えた互換性を確保するため、オープンコミュニティ標準として設計・開発されています。Hive、Impala、Spark、Trino、Flink、Prestoなどのエンジンが同じテーブルを同時に扱うことを可能にしながら、SQL テーブルの信頼性とシンプルさをビッグデータにもたらします。Apache Iceberg は、Cloudera Data Platform (CDP)と共に Cloudera の Open Data Lakehouse のコア基盤を形成しています。
マテリアライズド・ビューは、JOIN、GROUP BY、集約関数で構成され、また一般的なビジネスインテリジェンス (BI) ユースケースで使われる BI クエリを高速化するのに役立ちます。Hive を実行する Cloudera Data Warehouse (CDW) は、これまで Hive ACIDソーステーブルに対するマテリアライズド・ビューの作成をサポートしていました。CDW パブリッククラウド DWX-1.6.1 リリースとそれに対応する CDW プライベートクラウドデータサービスリリースから、Hive は Iceberg テーブル形式のマテリアライズド・ビューの作成、使用、再構築もサポートしています。
この機能の主な特徴は以下のとおりです:
- マテリアライズド・ビューのソース・テーブルは Iceberg テーブル (基礎となるファイル形式は Parquet や ORC) であること。
- マテリアライズド・ビュー自体が Iceberg テーブルであること。
- マテリアライズド・ビューは、1 つ以上の列でパーティショニングできる。
- JOIN、フィルタ、プロジェクション(射影)、GROUP BY、または GROUP BY なしの集約を含むクエリは、Hive オプティマイザによって、1つまたは複数の適格なマテリアライズド・ビューを使用するように透過的に書き換えることができる。これにより、大幅なパフォーマンス向上の可能性がある。
- マテリアライズド・ビューの完全な再構築 (フル・リビルド) と増分再構築 (インクリメンタル・リビルド) の両方がサポートされている。インクリメンタル・リビルドは、特定の条件下でのみ実行可能。
Iceberg マテリアライズド・ビューの作成
このブログの例では、TPC-DS データセットから store_sales、customer、date_dim の 3 つのテーブルをベース・テーブルとして使用します。
これらのテーブルは以下のようにIcebergテーブルとして作成します。
create table store_sales ( `ss_sold_time_sk` int, … … `ss_net_profit` decimal(7,2)) PARTITIONED BY ( `ss_sold_date_sk` int) stored by iceberg stored as orc ;
他の2つのテーブルも同様です。テキスト形式のソース・テーブルから読み込み、INSERT-SELECT ステートメントを使用してテーブルを作成しましたが、どのような ETL プロセスでも作成することができます。
マテリアライズド・ビューを作成してみましょう。この例では、3つのテーブルを結合し、フィルタ条件を持ち、グループ毎の集計を行います。このようなクエリー・パターンは、BI クエリーでは非常に一般的です。マテリアライズド・ビューの定義には、’stored by iceberg’ 節が含まれていることに注意してください。さらに、d_year 列でパーティショニングされています。
drop materialized view year_total_mv1; create materialized view year_total_mv1 PARTITIONED ON (dyear) stored by iceberg stored as orc tblproperties ('format-version'='2') AS select c_birth_country customer_birth_country ,d_year dyear ,sum(ss_ext_sales_price) year_total_sales ,count(ss_ext_sales_price) total_count from customer ,store_sales ,date_dim where c_customer_sk = ss_customer_sk and ss_sold_date_sk = d_date_sk and d_year between 1999 and 2023 group by c_birth_country ,d_year ;
マテリアライズド・ビューのメタデータを表示する
通常のテーブルと同様に、マテリアライズド・ビューに対する DESCRIBE 文を実行することでメタデータを表示できます。
DESCRIBE FORMATTED year_total_mv1;
主な特徴を以下のとおりです。(DESCRIBE 文の出力より抜粋)

上記のように、このマテリアライズド・ビューはクエリ書換えが有効になっており、古いものではありません。マテリアライズド・ビューに関係するソース・テーブルのスナップショット ID もメタデータに保持されます。その後、これらのスナップショット ID を使用して、マテリアライズド・ビューの行に適用するデルタ変更が決定されます。
SHOW MATERIALIZED VIEWS;

最後の列は、INSERT 操作がある場合にのみ、マテリアライズド・ビューはインクリメンタル・リビルドによりメンテナンスされる必要があることを示しています。UPDATE/DELETE/MERGE 操作によってベース・テーブルのデータが変更された場合、実体化されたビューは完全に再構築されなければなりません。 将来のバージョンでは、このような場合の増分再構築をサポートする予定です。
マテリアライズド・ビューは、書き換えを明示的に無効にすることもできます。これは、データベースにおいて、特定の理由でインデックスを無効にするのと似ています。
ALTER MATERIALIZED VIEW year_total_mv1 DISABLE REWRITE;
有効化するには以下のようにします。
ALTER MATERIALIZED VIEW year_total_mv1 ENABLE REWRITE;
マテリアライズド・ビューを使用したクエリプラン
まず、グループ化する列と集計式がマテリアライズド・ビューの1つと完全に一致する単純なケースを考えてみましょう。
explain cbo select c_birth_country customer_birth_country ,d_year dyear ,sum(ss_ext_sales_price) year_total_sales from customer ,store_sales ,date_dim where c_customer_sk = ss_customer_sk and ss_sold_date_sk = d_date_sk and d_year between 2000 and 2003 group by c_birth_country ,d_year ;
CBOプランは以下の通りです。
HiveProject(customer_birth_country=[$0], dyear=[$3], year_total_sales=[$1]) HiveFilter(condition=[BETWEEN(false, $3, 2000, 2003)]) HiveTableScan(table=[[tpcds_iceberg, year_total_mv1]], table:alias=[tpcds_iceberg.year_total_mv1])
上記のCBO (コスト・ベース・オプティマイザ) プランは、year_total_mv1 マテリアライズド・ビューのみがスキャンされ、フィルタ条件が適用されることを示しています。したがって、元のクエリの3つのテーブルのスキャンと結合が不要になり、I/O コストの節約と結合と集約を計算する CPU コストの節約の両方により、パフォーマンスが大幅に向上します。
ここで、クエリ内の group-by 式と集約式がマテリアライズド・ビューと完全に一致するわけではないが、マテリアライズド・ビューから派生した項目と一致する可能性がある、より高度な使用法を考えてみましょう。
explain cbo select c_birth_country customer_birth_country ,avg(ss_ext_sales_price) year_average_sales from customer ,store_sales ,date_dim where c_customer_sk = ss_customer_sk and ss_sold_date_sk = d_date_sk and d_year between 2000 and 2003 group by c_birth_country ;
CBO プランは以下のようになります。
HiveProject(customer_birth_country=[$0], year_average_sales=[CAST(/($1, COALESCE($2, 0:BIGINT))):DECIMAL(11, 6)]) HiveAggregate(group=[{0}], agg#0=[sum($1)], agg#1=[sum($2)]) HiveFilter(condition=[BETWEEN(false, $3, 2000, 2003)]) HiveTableScan(table=[[tpcds_iceberg, year_total_mv1]], table:alias=[tpcds_iceberg.year_total_mv1])
ここで、マテリアライズド・ビュー year_total_mv1 には、クエリの AVG(ss_ext_sales_price) 式を導出するために使用される SUM および COUNT 集約式が含まれています。さらに、このクエリには GROUP BY c_birth_country のみが含まれているため、c_birth_country で第2レベルのグループ化が行われ、最終的な出力が生成されます。
マテリアライズド・ビューのインクリメンタル・リビルドおよびフル・リビルド
ベース・テーブルに行を挿入し、マテリアライズド・ビューを更新して新しいデータを反映させる方法を検討します。

テーブルの変更により、Iceberg は新しいスナップショットを作成ます。メタデータの “snapshots “テーブルを調べることで、新しいスナップショットのバージョンを知ることができます。
SELECT * FROM tpcds_iceberg.store_sales.snapshots;
マテリアライズド・ビューの内容が古くなったため、クエリ書換えの対象から外されたことを確認してください。
DESCRIBE FORMATTED year_total_mv1;
Outdated for Rewriting: Yes がそれを示しています。
元のクエリを実行すると、マテリアライズド・ビューは利用されず、代わりにソース・テーブルのフル・スキャンが実行され、その後に JOIN と GROUP BY が実行されます。
マテリアライズド・ビューを再構築してみましょう。
ALTER MATERIALIZED VIEW year_total_mv1 REBUILD;
これは、store_sales テーブルから差分変更のみを読み取ることで、マテリアライズド・ビューの増分再構築を行います。Hive は Iceberg ライブラリに、マテリアライズド・ビューが最後に再構築または作成されたときの、そのテーブルの最後のスナップショット以降に挿入された行のみを返すように要求します。そして、他のテーブルと結合した後、これらの差分行の集約値を計算します。最後に、この行のセットは、グループ化列を結合キーとしてマテリアライズド・ビューと外部結合され、適切な集約値が統合されます。例えば、古い合計と新しい合計が加算され、新しい値が古い値より低いか高いかによって、古い最小/最大集約値が新しい値に置き換えられます
マテリアライズド・ビューの再構築は、ここでは手動でトリガーされますが、スケジュール実行により、定期的な間隔で実行することもできます。
この時点で、マテリアライズド・ビューはクエリ書換えに使用できるようになります。
DESCRIBE FORMATTED year_total_mv1; Outdated for Rewriting: No
と変更されており、クエリ書換えが無効化されていないことを示しています。
元のクエリを再実行すると、再びマテリアライズド・ビューが使用されます。
インクリメンタル・リビルドの適格条件
以下の状況では、インクリメンタル・リビルドはできません。
- ベース・テーブルが DELETE/MERGE/UPDATE 操作によって変更された場合。
- 集約関数が SUM、MIN、MAX、COUNT、AVG以外の場合。STDDEV、VARIANCE などの他の集約では、ベース・データのフル・スキャンが必要です。
- ソース・テーブルのいずれかが前回の再構築以降にコンパクションされた場合。コンパクションはマージされたファイルで構成される新しいスナップショットを作成するため、前回のリビルド操作以降の差分変更を判断することはできません。
このような状況では、Hive はフル・リビルドにフォールバックします。このフォールバックは、同じ REBUILD コマンドの一部として透過的に実行されます。
Iceberg マテリアライズド・ビュー仕様に関する注意
現在、マテリアライズド・ビューに必要なメタデータは Hive Metastore で管理されており、以前に Hive ACID テーブルでサポートされていたマテリアライズド・ビューのメタデータをベースにしています。この1年間で、Iceberg コミュニティはマテリアライズド・ビュー仕様を提案しました。将来的には、Hive Icebergのマテリアライズド ・ビュー サポートにこの仕様を採用する予定です。
マテリアライズド・ビューのパフォーマンス
Iceberg テーブル形式のマテリアライズド・ビューがある場合のクエリのパフォーマンスを評価するために、TPC-DS データセットを 1TB スケールファクタで使用しました。 テーブル形式は Iceberg でファイル形式は ORC でした(同様のテストは Parquet でも実行できますが、Hive のほとんどの顧客が ORC を使用しているため、ORC を選択しました)。ANALYZE コマンドを実行し、すべての基本テーブルのテーブルと列の統計情報を収集しました。
私たちは23の TPC-DS クエリから始め、それらのバリエーションを作成し、ワークロードに合計50のクエリを用意しました。各クエリには1つから3つのバリエーションがあり、以下の変更のうちのひとつをもとに作成されたものでした:
- GROUP-BY 句にカラムを追加する
- SELECT リストに集約関数を追加する
- (単一テーブルの WHERE 述語を追加または修正する
私たちは、50のクエリすべてについて、EXPLAIN CBO (コストベースの最適化) プランを JSON フォーマットで取得し、そのプランを Cloudera Data Warehouse でサポートされているマテリアライズドビューレコメンダーに供給しました。ランク付けされたレコメンデーションに基づいて、上位7つのマテリアライズド・ビューを選択し、それらを Iceberg テーブルフォーマットで作成しました。AWS 上の CDW Hive バーチャル・ウェアハウス上で、大きなサイジング (バーチャル・ウェアハウスのサイジングを参照してください) を使用して、50のクエリワークロードを実行しました。各クエリは3回実行され、実行時間の最小値を取得しました。マテリアライズド・ビューのクエリ書換えを有効にした場合としなかった場合のクエリパフォーマンスの結果を以下に示します。以下の設定オプションが有効になっています:
SET hive.materializedview.rewriting = false;
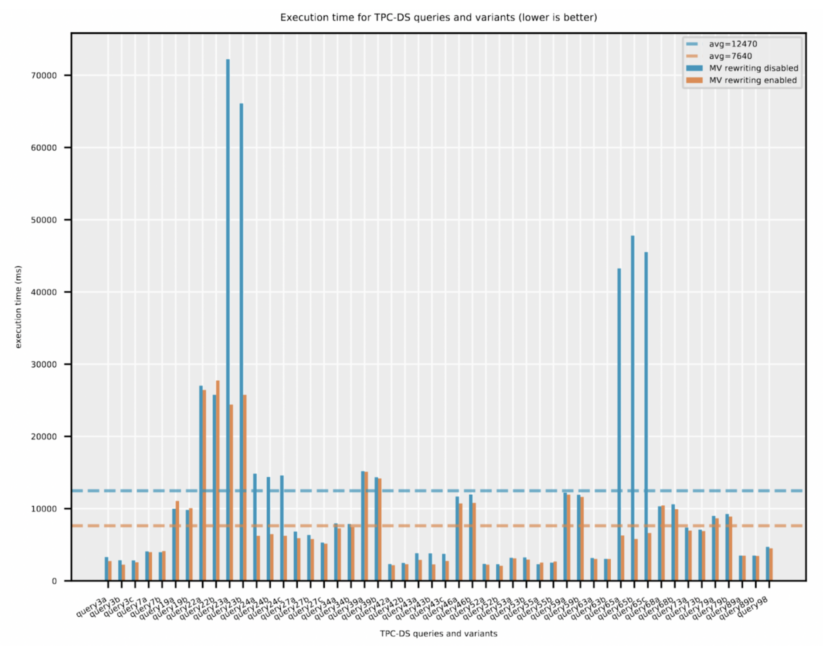
50のクエリのうち、オプティマイザがマテリアライズド・ビューを使用して実行計画を作成したクエリは16あります。例えば、query65 a, b, c のバリエーションでは、経過時間が85%近く短縮された。全体として、すべてのクエリにおいて、総経過時間の平均削減率は40%でした。また、マテリアライズド・ビューにヒットしなかったクエリのコンパイル時間のオーバーヘッドのみを調べました。オプティマイザがマテリアライズド・ビューの使用可能性を評価するため、平均クエリ・コンパイル時間が4% (約60ミリ秒) わずかに増加しました。
今回の性能評価では、マテリアライズド・ビューを使用したクエリの書き換え性能に焦点を当てました。今後のブログでは、インクリメンタルとフル・リビルドのパフォーマンスを評価します。
まとめ
このブログ記事では、Hive における Iceberg テーブル形式のマテリアライズド・ビューのサポートについて説明しています。この機能は、AWS と Azure 上の Cloudera Data Warehouse (CDW) Public Cloud デプロイメント、および CDW Private Cloud Data Services デプロイメントで利用できます。ユーザーは Iceberg ソーステーブル上にマテリアライズド・ビューを作成でき、Hive はこれらを活用してクエリパフォーマンスを高速化できます。ソーステーブルのデータが変更された場合、条件付き(上記)でマテリアライズド・ビューのインクリメンタル・リビルドがサポートされます。
Cloudera Data Platform のテーブルフォーマットとしての Apache Iceberg のサポートと、そのようなテーブルの上にマテリアライズド・ビューを作成して使用する機能は、オープンデータレイクアーキテクチャ上で高速な分析アプリケーションを構築するための強力な組み合わせです。次回のハンズオンラボにお申し込みいただき、Cloudera のレイクハウス上で Apache Iceberg をお試しいただき、マテリアライズド・ビューの利点と使いやすさをご確認ください。また、ウェビナーに申し込んで、Apache Iceberg の利点について詳しく学び、デモを見て最新の機能を確認することもできます。
謝辞
パフォーマンステストの評価にあたり、Soumyakanti Das 氏の協力を得たことに感謝します。
