

by WeiWei Yang, Wilfred Spiegelenburg, Kinga Marton
この記事は、2022/5/5に公開された「Spark on Kubernetes – Gang Scheduling with YuniKorn」の翻訳です。
Apache YuniKorn (Incubating) は 0.10.0 をリリースしました。(リリースはこちら) 今回のリリースでは、「Gang Scheduling (ギャングスケジューリング)」と呼ばれる新機能が利用できるようになりました。ギャングスケジューリング機能を活用することで、Kubernetes 上の Spark ジョブのスケジューリングがより効率的になります。
Apache YuniKorn (Incubating) とは何か
Apache YuniKorn (Incubating) は、Kubernetes 上で豊富なスケジューリング機能を提供する新しい Apache インキュベータプロジェクトです。階層型キュー、エラスティックなキューの割り当てクォータ、リソースのフェアな割り当て、ジョブの順序制御など、便利な機能を多数備え、Kubernetes 上でビッグデータワークロードを実行する際のスケジューリングのギャップを埋めることができます。YuniKorn の詳細は、以前の記事「YuniKorn – a universal resources scheduler」と「Spark on Kubernetes – how YuniKorn helps」をご確認ください。
ギャングスケジューリングとは何か
ウィキペディアによると、ギャングスケジューリングとは、並列システムのためのスケジューリングアルゴリズムで、関連するスレッドやプロセスを、異なるプロセッサ上で同時に実行するためにスケジューリングするものです。これは分散コンピューティングの世界では、相関のあるタスクを「All or Nothing (オールオアナッシング)」でスケジューリングする仕組みを指します。つまり、リソーススケジューラはタスク単位でスケジューリングするのではなく、アプリケーションに必要なスロットの数を総合的に判断し、その要求全体が満たされるタイミングでリソースを割り当てるか、その状態になるまでスケジューリングを先延ばしにするということです。
なぜ、ギャングスケジューリングが必要なのか
ギャングスケジューリングは、同時にタスクを起動する必要があるマルチタスクのアプリケーションで非常に有効です。これは、TensorFlow など、機械学習ワークロードに共通する要件となります。2つ目のユースケースは、ギャングスケジューリングにより、バッチジョブのリソースのセグメンテーションに関する問題を回避できることで、Spark のようなコンピューティングエンジンに非常に有効です。
ギャングスケジューリングにより、YuniKorn は、ひとつのキューの中でリソースの割り当てを超えずに実行可能なアプリケーションの数を「理解」し、その結果、そのキューの中で最大限のジョブを同時に実行できます。
YuniKorn のギャングスケジューリング
YuniKorn は、アプリケーションのギャング(後述)を定義するためにTaskGroups タイプを導入しています。これは、ギャングのスケジューリング要件を定義する一般的な方法で、あらゆるアプリケーションで利用することができます。TaskGroups タイプは名前からわかるとおり、各 TaskGroup はアプリケーションの「ギャング」を表し、それは均質なポッドリクエストのグループです。タスクグループの定義方法については、こちらのドキュメントを参照してください。
TaskGroups を持つアプリが送信されると、ギャングスケジューリングが行われます。。アプリのポッドに対して直接リソースを割り当てる代わりに、異なる手順でスケジューリングを行います。スケジューリングの手順は、主に4つのフェーズで構成されています。
準備:このフェーズでは、YuniKorn は TaskGroups の定義に基づいて、一定の数のプレースホルダーポッドをプロアクティブに作成します。各タスクグループの中に、このグループに対して定義されたリソースと制約を使用して、mimMember パラメータで指定された数のプレースホルダポッドが作成されます。
リソース予約: このフェーズでは、YuniKorn はプレースホルダーポッドにリソースを割り当て、すべてのリソースが割り当てられるのを待ちます。プレースホルダーポッドは、ノード上のスポットを確保するために軽量の「pause」コマンドを実行しているだけです。
スワップ:すべてのプレースホルダーが割り当てられると、YuniKorn はプレースホルダーポッドを「スワップ」することで、リソースを実際のアプリのポッドに割り当て始めます。プレースホルダーポッドのリソースは、同じグループ内の実際のポッドとまったく同じになっているので、軽微な処理でスワップを行うことが可能です。。YuniKorn は確保された場所に実際のポッドを配置するよう最善を尽くしますが、そうでない場合は他の適格なノードにフォールバックします。
ファイナライズ:このフェーズでは、YuniKorn はアプリのリソースの割り当てを終了し、必要なクリーンアップ処理を開始します。プレースホルダーポッドがどの taskGroup からも必要とされなくなった場合 (例:過剰予約など)、それらはガベージコレクションされます。
ギャングスケジューリングによる Spark ジョブのスケジューリング
ギャングスケジューリングを行わない場合、YuniKorn の Spark ジョブスケジューリングは StateAware ポリシーに基づいて行われ、このポリシーは競合状態を避けるためにジョブ間に小さなスケジューリング遅延を設定します。しかし、クラスタがオートスケーリングに大きく依存している場合、これは非効率性が生じます。ギャングスケジューリングは、これらの問題を解決し、より効率的にジョブをスケジューリングします。以下はSpark ジョブでギャングスケジューリングを有効にした場合の例です。
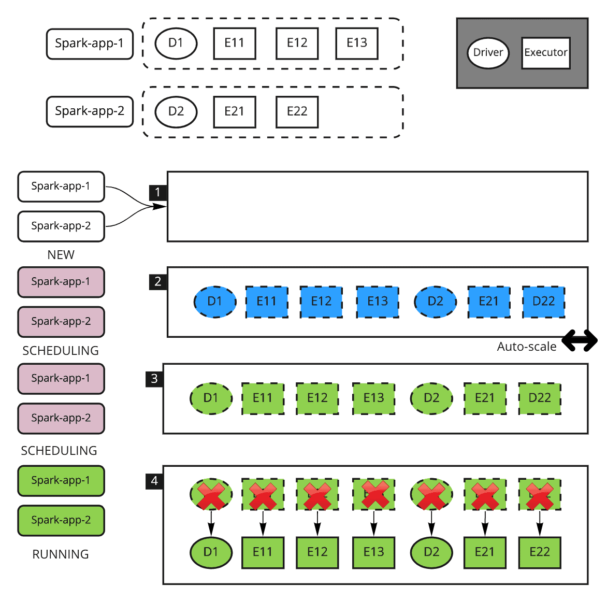
説明:
- 2つの Spark ジョブが同時にリソースキューに送信されます。
- Kubernetes 上に2つの Spark ドライバーポッドが割り当てられると、YuniKorn は TaskGroups 定義からギャングスケジューリングのメタデータを取得し、プレースホルダーポッドをプロアクティブに生成して各ジョブに必要なリソースを確保し始めます。このステップでは、クラスタでオートスケーラーが有効になっている場合、プレースホルダーポッドがアップスケーリングを開始します。ドライバーがエグゼキュータを作成するのを待つ必要がないため、アップスケーリングは以前よりずっと早く開始されます。
- クラスタがスケールアップすると、プレースホルダーが割り当てられます。
- すべてのプレースホルダーが割り当てられると、YuniKorn は TaskGroup 内のプレースホルダーポッドと実際のポッドの入れ替えを開始し、すべての実際のポッドが割り当てられるまで続けられます。そして、2つのジョブが実行されます。
メリット
リソースセグメンテーションの問題を回避する
リソースセグメンテーションの問題は、クラスタが受け取るすべてのジョブに対して十分なリソースを持っていない場合に非常によく発生します。以下の図では、緑のボックスがジョブの割り当て済みポッド、赤のボックスが割り当て待ちのポッドを表しています。リソースが十分でないクラスタ上でジョブを同時に実行すると、以下のように、ジョブ同士がリソースを巡ってお互いに競合状態に陥る可能性があります。
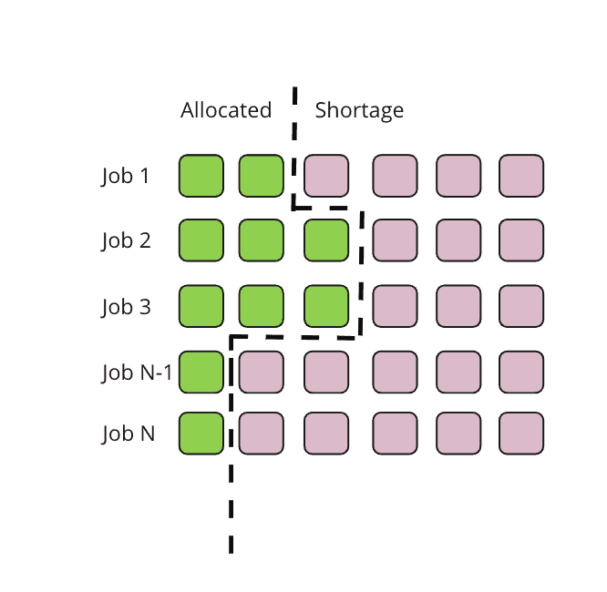
1 から N までのジョブには、必要なリソースが部分的に割り当てられていますが、すべての必要なリソースが割り当てられているわけではありません。これは非常に非効率的です。最悪の場合、各ジョブに割り当てられるポッドは1つだけとなります。Sparkでこのようなことが起こると、ドライバーポッドだけが起動した状態で、エグゼキュータ用のリソースが残らないため、すべてのジョブが実行不能になります。
ギャングスケジューリングでは、スケジューラが各ジョブの起動に必要な最小限のリソースを確保することを保証します。同じシナリオでも、このようになります。
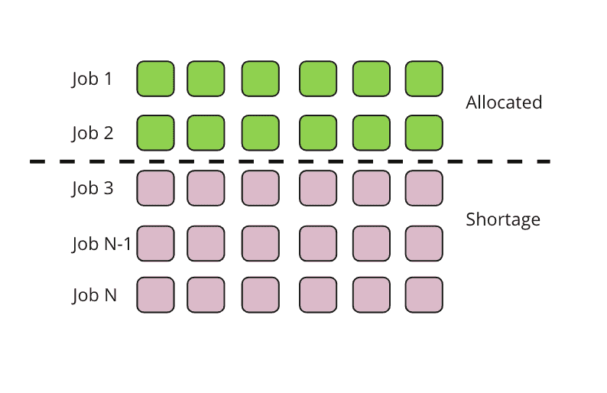
この場合、ジョブ1とジョブ2の2つのジョブがキュー内のリソースをすべて使用しているため、ジョブ1とジョブ2のみにリソースが割り当てられます。残りのジョブは、ジョブ1またはジョブ2がリソースを解放するまで保留されます。こうすることで、ジョブの実行時間がより予測しやすくなり、リソースのセグメンテーションやデッドロックの問題も発生しなくなります。
クラウド上で Spark を実行する際のパフォーマンス向上
クラウドが与えてくれる最大の恩恵の1つは柔軟性です。クラスタは、クラスタオートスケーラーの存在によってオンデマンドで成長したり縮小したりすることができます。ギャングスケジューリングを使用しない場合、Kubernetes 上の Spark のスケジューリングは以下のようになります。
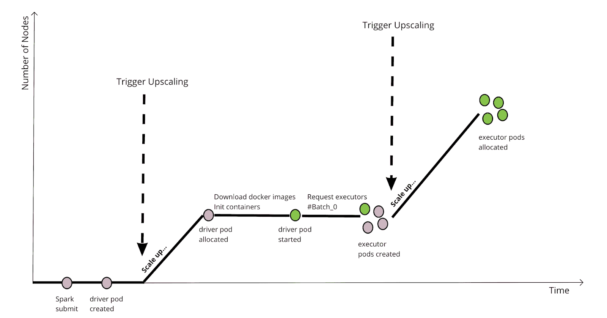
この図は、利用可能なコンピュートノードが0台の「コールド」クラスタに Spark ジョブを投入するシナリオを示しています。このシナリオでは、クラスタを目的のサイズにスケールアップするためには、いくつかのステップが必要です。Docker イメージのダウンロード、Spark ドライバーの初期化、依存関係のダウンロード、エグゼキュータのリクエストなどに時間がかかるため、2つのトリガーの間に大きな遅延が発生します。ドライバーがエグゼキュータをバッチで適用すると、これはさらに悪化します。
ギャングスケジューリングでは、ワークフローが以下のように変わります。
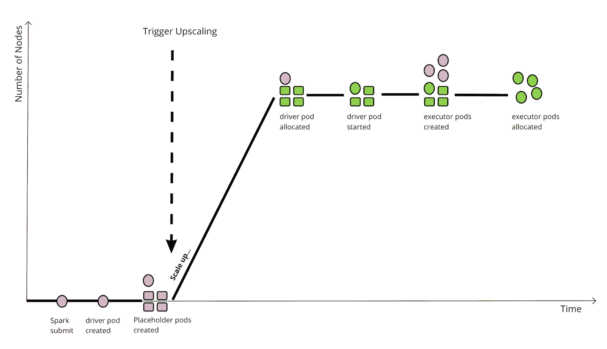
Spark がドライバー/エグゼキュータポッドを作成してアップスケーリングを開始するのを待つかわりに、Yunikornはあらかじめプレースホルダーポッドを作成し、これがアップスケーリングをひとつの大きなステップとして開始するトリガーとなり、クラスタを目的のサイズに直接スケールさせます。そして、残りのステップは、もうクラスタのアップスケーリングを待つ必要はありません。これは、各Sparkジョブが異なるバッチを持つ場合や、クラスタに投入されるバッチジョブがある場合に、より効率的です。
次のステップ
YuniKorn コミュニティは、Spark K8s オペレータとのさらなる統合に取り組み、ギャングスケジューリングを使用して Kubernetes 上で Spark を実行するエンドツーエンドの体験を提供することを目的としています。この問題は、YUNIKORN-643 で追跡調査されています。
その他のリソース
ギャングスケジューリング機能は、Apache YuniKorn (Incubating) 0.10リリースで利用できるようになりました。 (リリースアナウンスメント) ギャングスケジューリングの使用方法については、ギャングスケジューリングユーザーガイドをお読みください。設計の詳細を理解したい方は、こちらの設計ドキュメントをご覧ください。また、過去のブログ (英語版) でも情報を発信していますので、合わせてご確認ください。
