

by Sunil Govindan, WeiWei Yang, Wangda Tan, Wilfred Spiegelenburg
この記事は、2020/10/14に公開された「Apache Spark on Kubernetes: How Apache YuniKorn (Incubating) helps」の翻訳です。
背景
Apache Spark に K8s を選ぶべき理由
Apache Spark によって、バッチ処理、リアルタイム処理、ストリーム解析、機械学習、インタラクティブクエリを1つのプラットフォームに統合できます。Apache Spark は、多様なユースケースをサポートするために多くの機能を提供する一方で、クラスタ管理者にとっては、さらなる複雑さをもたらし、高いメンテナンスコストにつながる面もあります。Spark がワンプラットフォームとして力を発揮するために、基盤となるリソースオーケストレーターに求められる大まかな要件を見てみましょう。
- 異なる ML および ETL ジョブ間で共有されるリソースを提供できる、コンテナ化されたSparkコンピュート
- イテレーションの高速化と安定した運用をともに実現するための、複数の Spark バージョン、Python バージョンのサポート、および共有のk8sクラスタ上で動くバージョン管理されたコンテナ大多数のバッチワークロードとマイクロサービスの両方に対応する単一の統一されたインフラストラクチャ
- 共有クラスタにおけるきめ細かなアクセス制御
サービスデプロイメントの事実上の標準である Kubernetes は、他のリソースオーケストレーターと比較して、上記のすべての側面でよりきめ細やかな制御を行うことができます。Kubernetes は、ワークロードの分離、リソースの使用制限、オンデマンドのリソースデプロイメント、必要に応じた自動スケーリング機能など、実用的なアプローチでインフラとアプリケーションをよりシンプルに管理する方法を提供します。
K8s で Apache Spark を動作させるためのスケジューリングの課題
長時間稼働するサービスがスケジュールされているのと同じクラスタに、バッチのワークロードもデプロイする場合、Kubernetes のデフォルトスケジューラは、効率性においての課題があります。バッチ処理のワークロードは、並列処理による計算が要求されるという性質上、ほとんどが同時に、かつより頻繁にスケジュールされることになります。その課題のいくつかの詳細を見ていきましょう。
ファーストクラスのアプリケーション概念の欠如
バッチ処理は多くの場合、コンテナのデプロイメントの種類に応じて、連続的にスケジュールされる必要があります。例えば、Spark ドライバーポッドは、ワーカーポッドよりも早くスケジューリングする必要があります。明確なファーストクラスのアプリケーション概念は、各コンテナのデプロイメントの順序やキューイングの際に役立ちます。また、このような概念は、管理者がデバッグのためにスケジュールしたジョブを可視化するのに役立ちます。
効率的な容量/クォータ管理能力の欠如
Kubernetes における名前空間ごとのリソースクォータは、マルチテナントのユースケースで、Spark ワークロードを実行しながらリソースを管理するために使用することができます。ただし、これを実現するには、いくつかの課題があります。
- Apache Spark のジョブは、そのリソースの使用に関して動的な性質を持っています。名前空間クォータは固定で、アドミッションフェーズでチェックされます。ポッドのリクエストは、名前空間のクォータに収まらない場合、拒否されます。このため、Apache Spark をKubernetes 上で動かす際は、Kubernetes 自体の中でリクエストをキューイングするのではなく、ポッドのリクエストをリトライする仕組みをApache Spark 側で実装することが必要になります。
- 名前空間のリソースクォータはフラットで、階層的なリソースの割り当て管理はサポートされていません。
また、Kubernetes の名前空間のクォータは組織階層に基づく容量配分計画と一致しないことが多いため、バッチ処理を実行するためのリソースが足りなくなることがありました。。現時点では、K8s において、エラスティックで階層的なジョブの優先度管理の仕組みはありません。
テナント間のリソースの公平性の欠如
本番環境において、Kubernetes のデフォルトスケジューラでは、多様化したワークロードを効率的に管理できず、ワークロードのリソースの公平性を提供できないことがよくあります。主な理由としては、以下のようなものがあります。
- 本番環境でのワークロードバッチ管理は、多くの場合、多数のユーザーで実行される
- さまざまな種類のワークロードが稼働する高密度な本番環境では、Spark のドライバーポッドが名前空間内のすべてのリソースを占有してしまう可能性が高くなる。このようなシナリオは、効果的なリソース共有に大きな課題をもたらす
- 非常に多くのリソースを使用するジョブや破損したジョブは、簡単にリソースを奪い、本番のワークロードに影響を与える可能性がある
スケジュール遅延に関する厳しい SLA 要件
バッチ処理に特化したビジーなプロダクションクラスタの多くは、毎日数十万のタスクからなる数千のジョブを実行することがよくあります。これらのワークロードでは、より大量のコンテナの並列デプロイメントが必要となり、そのようなコンテナの寿命は短いこと(数秒から数時間)がよくあります。そのため、通常、何千ものポッドやコンテナのデプロイがスケジュールされるのを待っています。Kubernetes のデフォルトスケジューラを使用すると、さらに遅延が発生し、SLA を逸脱する可能性があります。
Apache YuniKorn (Incubating) でできること
Apache YuniKorn (Incubating) の概要
YuniKorn は、サービスとバッチワークロードの両方に対応する拡張 Kubernetes スケジューラです。YuniKorn は、Kubernetes のデフォルトスケジューラを置き換えることも、デプロイのユースケースに応じて K8s のデフォルトスケジューラと連携することも可能です。
YuniKorn は、ステートレスバッチワークロードとステートフルサービスからなる混合ワークロードに対して、統一されたクロスプラットフォームのスケジューリング体験を提供します。
YuniKorn 対Kubernetes のデフォルトスケジューラ比較
| 特徴 | デフォルト
スケジューラ |
YUNIKORN | 備考 |
| アプリケーションコンセプト | x | √ | YuniKornでは、アプリケーションは第一級オブジェクトです。YuniKorn は、アプリの実行順、優先度、リソースの使用状況などを考慮してスケジュールを設定します。 |
| ジョブの順序制御 | x | √ | YuniKornはFIFO/FAIR/Priority (WIP) のジョブ順序制御ポリシーをサポートしています。 |
| きめ細かなリソース容量管理 | x | √ | クラスタリソースを階層キューで管理します。キューは、保証されたリソース (最小) とリソースクォータの上限 (最大) を提供します。 |
| リソースの公平性 | x | √ | アプリケーションとキュー間のリソースの公平性を確保し、実行中のすべてのアプリケーションに理想的な割り当てを行う。 |
| ビッグデータワークロードをネイティブにサポート | x | √ | デフォルトのスケジューラは長時間稼働するサービスに重点を置いています。YuniKornは、ビッグデータアプリケーションのワークロード向けに設計されており、Spark / Flink / Tensorflow などを K8s で効率的に実行することをネイティブにサポートします。 |
| スケールとパフォーマンス | x | √ | YuniKorn はパフォーマンスに最適化されており、高スループットかつ大規模な環境に適しています。 |
Kubernets上でSparkを稼働させる際、YuniKorn がどのように役に立つか
YuniKorn は、Kubernetes 上で Apache Spark を大幅に効率的に実行するための豊富な機能を備えています。K8s で YuniKorn を使って Spark を実行する詳しい手順はこちらをご覧ください。
YuniKorn が K8s 上で Spark の実行する際にどのように役立つかについては、Spark & AI summit 2020 の 「Cloud-Native Spark Scheduling with YuniKorn Scheduler」で詳しく説明されています。
ここでは、いくつかのユースケースを紹介し、これらのシナリオで YuniKorn が Spark のリソーススケジューリングの改善にどのように役立っているかを見てみましょう。
複数の(ノイジーな)ユーザー が異なる Spark ワークロードを同時に実行する
多くのユーザーが一斉にジョブを実行し始めると、リソースの公平性、優先順位などを考慮して、ジョブに必要なリソースを分離して提供することが非常に難しくなります。YuniKorn スケジューラは、リソースキューを利用してリソース割り当て管理の最適解を提供します。
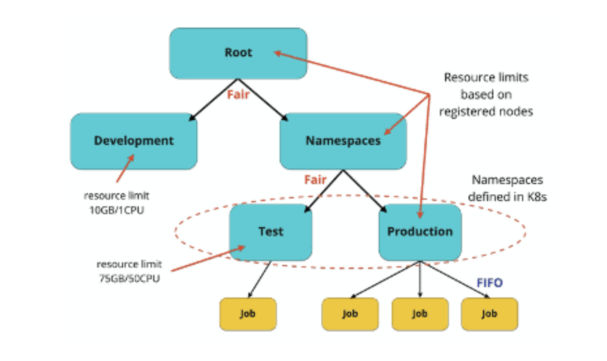
上記の YuniKorn のキュー構造の例では、Kubernetes で定義された名前空間が、配置ポリシーを使って「Namespace」の親キューの下のキューにマッピングされています。「Test」キューと「Development」キューは、リソースの上限が決まっています。他のすべてのキューの制限は、クラスタのサイズだけです。リソースはキュー間で「Fair」ポリシーにより分配され、ジョブは本番キューで「FIFO(先入れ先出し)」方式でスケジューリングされます。
利点の一部を大まかに説明すると、次の通りです。
- 1つの YuniKorn キューは、Kubernetesの1つの名前空間に自動的にマッピングできる
- キュー容量は、設定された最小値から最大値までの範囲でエラスティックにリソースを提供できるリソース不足を回避するためのリソースの公平性を確約する
YuniKorn は、Kubernetes クラスタのリソースクォータをシームレスに管理する方法を提供し、名前空間リソースクォータの代わりとして機能することができます。YuniKorn のリソースクォータ管理は、ポッドリクエストのキューイングと、プラグイン可能なスケジューリングポリシーに基づくジョブ間の限られたリソースの共有を活用できます。これは、Apache Spark 上で、ポッドの実行リトライするなどの追加要件なしで実現できます。
クラスタに組織の階層に基づくリソース割り当てモデルへを設定する
大規模な本番環境では、複数のユーザーがさまざまな種類のワークロードを一緒に実行することになります。多くの場合、これらのユーザーは、組織のチーム階層の持つ予算の制約に基づいてリソースを消費することになります。このようなプロダクションセットアップは、リソースクォータの境界内でクラスタリソースを効率的に使用するのに役立ちます。
YuniKorn は、クラスタ内のリソースをキューの階層構造で管理する機能を提供します。組織階層のような明確な階層構造を持つリソースキューを利用することで、マルチテナント環境におけるきめ細かなリソース容量管理が可能になります。YuniKorn のキューは静的にも動的にも構成でき、動的なキュー管理機能では、ユーザーが配置ルールを設定してキュー管理を委任できます。
マルチテナントクラスタにおける Spark ジョブ SLA の改善
マルチテナントクラスタで実行される通常の ETL ワークロードでは、希望する組織のキュー階層でジョブを実行するために、きめ細かいポリシーを簡単に定義する手段が必要です。このようなポリシーは、ジョブの実行に対してより厳格な SLA を定義するのに役立ちます。
YuniKorn は、FIFO や FAIR など、よりシンプルなポリシーに基づいてキュー内のジョブの順序付けを可能にするオプションを管理者に提供します。ステートアウェアなアプリケーションのソーティングポリシーは、キュー内のジョブを FIFO(先入れ先出し) 順に並べ、条件に従って1つずつスケジュールします。これにより、Spark などの多くのバッチジョブを単一の名前空間(またはクラスタ)にで実行する際によくある競合状態を回避することができます。また、ジョブの特定の順序を強制することで、ジョブのスケジューリングをより予測可能なものに改善します。
Apache Spark ジョブスケジューリングのためのさまざまなK8s機能セットの有効化
YuniKorn は、K8s の主要なリリースバージョンと完全な互換性があります。ユーザーは、既存の K8s クラスタ上でスケジューラを透過的に交換することができます。YuniKorn は、ラベルセレクタ、ポッドアフィニティ/アンチアフィニティ、テイント/トレレーション、PV/PVCなど、スケジューリング時に使用できるすべてのネイティブ K8s セマンティクスを完全にサポートしています。YuniKorn は、cordon ノード、kubectl によるイベントの取得など、管理コマンドやユーティリティにも対応しています。
CDPのApache YuniKorn (Incubating)
Cloudera の CDP プラットフォームでは、Apache YuniKorn (Incubating) を利用した Cloudera Data Engineering 体験を提供します。
Cloudera で YuniKorn によって解決された大まかなユースケースには以下があります。
- CDE 仮想クラスタに対するリソースクォータ管理の提供
- Spark の高度なジョブスケジューリング機能の提供
- マイクロサービスおよびバッチジョブのスケジューリングを担当
- オートスケーリングを有効にした状態でのクラウド上の実行
Sparkワークロードを最適にサポートするための今後のロードマップ
YuniKorn コミュニティは、Spark ワークロードの実行をサポートするためのコア機能の拡張を積極的に検討しています。大まかな機能の一部としていくつかご紹介します。
Spark のワークロードでは、より効率的な実行のために、最小数のドライバとワーカーポッドを割り当てることが不可欠です。ギャングスケジューリングは、Spark ジョブの実行を開始するために必要な数のポッドを確実に割り当てるのに役立ちます。このような機能は、ノイズの多いマルチテナントクラスタのデプロイメントに非常に役立ちます。詳しくは、YUNIKORN-2 Jira にて進捗を追っています。
ジョブ/タスクの優先順位付けをサポート
ジョブレベルの優先順位付けにより、管理者はYuniKornに優先順位を付け、SLAに基づく優先順位の高いジョブ実行に必要なリソースを提供するよう指示することができます。また、クラスタリソースをより柔軟に有効活用することができます。詳しくは、YUNIKORN-1 Jira にて進捗を追っています。
分散型トレース
YUNIKORN-387 は Open Tracing を活用し、スケジューラ全体の観測可能性を向上させています。この機能により、トラブルシューティング、システムプロファイリング、監視のために、コアスケジューリングサイクルの重要なトレースを収集し、保持することができます。
まとめ
YuniKorn は、大規模なマルチテナント環境で効率的にさまざまな Spark ワークロードのきめの細かいリソース共有を実現し、一方ではクラウドネイティブな環境の動的な構築に役立ちます。
YuniKorn は、Apache Spark をエンタープライズグレードの必須プラットフォームとして強化し、大規模なデータ変換から分析、機械学習まで、さまざまなアプリケーションに対応する堅牢なプラットフォームを提供します。
謝辞
Shaun Ahmadian と Dale Richardson によるレビューとコメントに感謝しています。さらに、機能を最新の Apache リリースに搭載するために協力してくれた YuniKorn オープンソースコミュニティのメンバーにも心から感謝を申し上げます。
