

by Bill Zhang, Shaun Ahmadian, Peter Vary, Marton Bod, and Wing Yew Poon
この記事は、2022/2/22に公開された「Introducing Apache Iceberg in Cloudera Data Platform」の翻訳です。以下全ての情報は原文の公開時点のものになります。
過去10年間、大規模なデータプラットフォームの導入が行われてきました。その成功は、ビッグデータの需要促進となり、より多くのデータを取り込み、より高度な分析を適用することを促進してきました。また、ビジネスアナリストからデータサイエンティストに至るまで、多くの新しいデータ実務者の雇用の高まりに繋がっています。この前例のないレベルのビッグデータに対するワークロードには、それ相応の課題が伴います。 データアーキテクチャのレイヤは、データセットの増加によりスケーラビリティとパフォーマンスの限界が押し上げられている領域の1つです。データの爆発的な増加には、新しいソリューションが必要です。そのため、Cloudera Data Platform (CDP) に大規模分析データセット用の次世代のテーブルフォーマットである Apache Iceberg を導入することになりました。そして、Cloudera Data Warehousing (CDW) および Cloudera Data Engineering (CDE) を含むパブリッククラウドの CDP データサービス向けIcebergのプライベートテクニカルプレビュー (TP) リリースを発表いたしました。
Apache Icebergは、ペタバイトスケールの分析データセットを対象とした新しいオープンテーブルフォーマットです。これは、言語や実装の互換性を確保するため、オープンコミュニティ標準として設計・開発されています。Apache Iceberg はオープンソースで、Apache Software Foundation を通じて開発されています。そして、Adobe、Expedia、LinkedIn、Tencent、Netflix などの企業が、大規模な分析データセットの処理に Apache Iceberg を採用したことをブログで発表しています。
ハイブリッドクラウドやマルチクラウドが提供する柔軟性をもって、大規模データセットの多機能分析を実現するために、Cloudera は Apache Iceberg と CDP を統合し、お客様のデータアーキテクチャを将来にわたっても確実にできる独自のソリューションとしました。CDW、CDE、Cloudera Machine Learning (CML) を含む様々なCDPデータサービスを Iceberg で最適化することで、SQL コマンドでデータセットを定義および操作、Time Travel 操作などの機能を使用して複雑なデータパイプラインを構築、Iceberg テーブルから構築された機械学習モデルを展開することもできます。そして、Shared Data Experience (SDX)、統合管理、ハイブリッドクラウドやマルチクラウドへの展開といった CDP のエンタープライズ機能をお客様に提供しています。それに加えて、Cloudera が大規模分析データセットのための次世代テーブルフォーマットである Apache Iceberg に貢献することによって、そのメリットをお客様にも活用いただけるのです。
主な設計目標
Apache Iceberg を CDP と統合するにあたり、新しいテーブルフォーマットの利点を取り入れるだけでなく、セキュリティや多機能分析など、最新化する企業のニーズに対応できるよう、その機能を拡張したいと考えました。そのため私たちは、多機能分析プラットフォーム全体で大規模データセットのスケーラビリティ、パフォーマンス、使いやすさを向上させる次のようなイノベーション目標を設定しました。
多機能分析:Iceberg はオープンでエンジンに依存せず、データセットを共有できるように設計されています。その開発に貢献することで、Hive と Impala のサポートを拡張し、大規模なデータ エンジニアリング (DE) ワークロードから高速 BI、クエリ (DW 内)、機械学習 (ML) までの多機能分析のためのデータアーキテクチャのビジョンを実現しました。
高速な実行計画:実行計画は、SQLクエリに必要なテーブル内のファイルを見つけるプロセスです。Iceberg では、実行計画のためにO(n)個のパーティション (実行時のディレクトリリスト) をテーブルにリストアップする代わりに、スナップショットを読み込むためにO(1)個のRPCを実行します。高速な実行計画により、低レイテンシの SQL クエリが可能になり、クエリ全体のパフォーマンスが向上します。
統合セキュリティ:Icebergと統合セキュリティレイヤとの統一は、あらゆるエンタープライズにとって重要です。そのため、はじめから SDX のセキュリティとガバナンスが Iceberg のテーブルにも適用されるようにしました。
物理的レイアウトと論理的レイアウトの分離:Iceberg は非表示のパーティショニングをサポートしています。ユーザーは、SQLクエリのパフォーマンスを最適化するためにテーブルがどのようにパーティション化されているかを知る必要はありません。Icebergテーブルは、データボリュームの変化に応じて、時間の経過とともにパーティションスキーマを進化させることができます。コストのかかるテーブルの書き換えは必要なく、多くの場合、クエリも書き換える必要はありません。
効率的なメタデータ管理:すべての Hive テーブルパーティション (パーティションのキーと値のペア、データの場所、その他のメタデータ) を追跡する必要がある Hive メタストア (HMS) とは異なり、Iceberg パーティションはファイルシステム上の Iceberg メタデータファイルにデータを保存します。これにより、メタストアおよびメタストアのバックエンドデータベースからの負荷が軽減されます。
この後のセクションでは、パフォーマンスと使いやすさの分野における重要な課題に対処するために、CDP 内に Apache Iceberg をどのように統合するかを詳しく見ていきます。 また、TPリリースで期待できることや、お客様へのメリットとなる独自機能についても触れたいと思います。
Apache Iceberg in CDP :当社のアプローチ
Iceberg は、様々なプラットフォームに接続できる、明確に定義されたオープンテーブルフォーマットを提供します。これには、スナップショットへのアトミックな変更をサポートするカタログが含まれています。これは、Iceberg テーブルへの変更が成功したか失敗したかを確実に知るために必要です。さらに、ファイルI/Oの実装は、ファイルの読み取り/書き込み/削除の方法を提供します。これは、明確に定義された API でデータとメタデータファイルにアクセスするために必要です。
これらの特徴と既存の実装により、Iceberg を CDP に統合するのは非常に簡単でした。 CDP では、Iceberg テーブルを Hive テーブルタイプと並行して使用できるようにしています。これらは両方とも SDX メタデータおよびセキュリティフレームワークの一部です。SDXとそのネイティブメタストアを活用することで、Iceberg テーブルを識別するためにカタログ情報の小さなフットプリントが登録され、インタラクションを軽量に保つことで、メタデータの保存とクエリにかかる通常の経費を発生させることなく、大規模なテーブルへの拡張が可能になります。
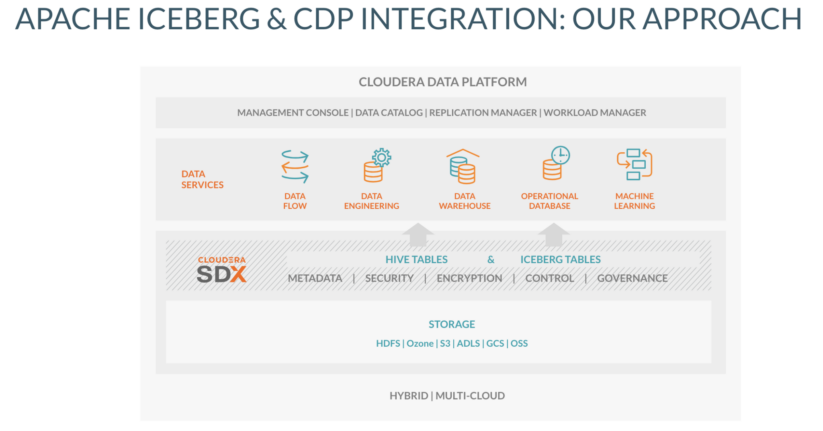
多機能分析
SDX で Iceberg テーブルが使用可能になったら、次のステップは、実行エンジンが新しいテーブルを活用できるようにすることです。Apache Iceberg コミュニティには、実行エンジンを統合したベテランの Spark 開発者による、膨大な貢献があります。一方で、Hive と Impala の Iceberg との統合については不十分だったため、Cloudera がコミュニティに還元しました。
ここ数ヶ月の間に、私たちは Hive の書き込み (すでに利用可能なHive の読み込みを上回る) と Impala の読み込みと書き込みの両方を有効にするという点で大きな進歩を遂げてきました。Iceberg テーブルを使えば、データをより積極的にパーティショニングできます。一例として、再パーティション化を行ったお客様で、Impala のクエリを使用した場合、Iceberg のテーブルのパフォーマンスが、以前使用していた Hive の外部テーブルの10倍優れていたことがわかったケースもあります。以前は、このような積極的なパーティショニング戦略はメタストアテーブルでは不可能でした。パーティションの数が多いと、これらのテーブルに対するクエリのコンパイルが遅くなるからです。これは、Iceberg がなぜこのような大きなスケールで優れた実力を発揮できるのかの良い例です。
統合セキュリティ
Iceberg のテーブルを SDX に統合すると、すぐに活用できる Ranger とも統合されるという利点があります。管理者は、Ranger の機能を活用し、特定のユーザーグループに対してテーブル全体、列、行を制限することができます。Hive と Impala の両方で、カラムをマスクし、値を編集/無効化/ハッシュ化することができます。CDPは、Iceberg テーブルのきめ細かなアクセスコントロールに独自の機能を提供し、セキュリティとガバナンスに対するエンタープライズの要求を実現します。
外部テーブルの変換
外部テーブルに保存されている既存の ORC、Parquet、Avro データセットを引き続き使用するために、現在の Spark に加えて Hive のサポートを追加することで、これらのテーブルを Iceberg テーブル形式に移行するための既存のサポートを統合および強化しました。テーブルの移行では、すべてのデータファイルをそのまま残し、コピーは作成せず、必要な Iceberg メタデータファイルのみを生成し、1回のコミットで公開されます。移行が正常に完了すると、それ以降のテーブルの読み書きはすべてIceberg を経由するようになり、テーブルの変更が新しいコミットを生成するようになります。
次のステップ
まず、追加のパフォーマンステストに焦点を当てて、特定したボトルネックを確認して削除します。これは、CDE、CDW をはじめとしたすべての CDP データサービスに適用します。製品公開に向けて、Apache Iceberg を使用した Spark ETL/ELT や Impala BI SQL 分析などの特定のワークロードパターンをターゲットにします。
そして以降も、新しいデータアーキテクチャ上での多機能分析という、先述のビジョンを実現するために、他のワークロードパターンのサポートを拡大していく予定です。そのため、Apache Iceberg と CDP の統合を以下の機能に沿って強化したいと考えています。
- ACIDサポート:Iceberg v2 フォーマットは、2021年8月のIceberg 0.12 でリリースされ、ACIDの基礎を築きました。新バージョンが提供する行レベルの削除などの新機能を利用するためには、Hive と Impala の統合においてさらなる機能強化が必要です。これらの新しい統合により、Hive と Spark は Iceberg v2 のテーブルに対して UPDATE、DELETE、MERGE 文を実行できるようになり、Impala はそれらを読み込めるようになります。
- テーブルレプリケーション:ディザスタリカバリやパフォーマンス上の理由から、エンタープライズが必要とする重要な機能です。Iceberg テーブルはレプリケーションを容易にしますが、ユーザーエクスペリエンスをシームレスにするためには、CDP Replication Manager との統合が必要です。
- テーブル管理:Iceberg テーブルは、ファイルリストとそれに伴うコストを回避することで、ハイブACIDテーブルよりも長い履歴を保存することができます。今後は自動スナップショット管理とコンパクションを有効にし、関連するスナップショットのみを保持し、クエリに最適化された形式にデータを再構築することで、Iceberg テーブル上のクエリのパフォーマンスをさらに向上させる予定です。
- Time Travel:検討しているTime Travel機能には、2つの時点間の変化セット (デルタ) のクエリ (betweenやsinceなどのキーワードを使用する可能性) などがあります。これらのクエリの正確なシンタックスとセマンティクスは現在設計・開発中です。
体験してみませんか?
大規模なデータセットに課題を抱えている方、スナップショットや Time Travel によるデータセット管理の最新イノベーションを活用したい方は、ぜひ CDP をお試しください。マルチクラウド、多機能分析プラットフォームにおける Apache Iceberg の利点をご自身でご確認いただけます。Apache Iceberg と CDP の統合についてご興味のある方は、貴社を担当するアカウントチームまでお問い合わせください。
CDW と CDE をお試しいただくには、60日間のトライアルにご登録いただくか、CDP のテストドライブをお試しください。フィードバックもお待ちしています。
