

by Bill Zhang, Peter Ableda, Shaun Ahmadian, and Manish Maheshwari
この記事は、2022/08/08に公開された「How to Use Apache Iceberg in CDP’s Open Lakehouse」の翻訳です。
2022年6月、ClouderaはCloudera Data Platform(CDP)でのApache Icebergの一般提供を発表しました。Icebergは、Apache Software Foundationを通じて開発された100%オープンテーブル形式で、ユーザーがベンダーロックインを回避し、オープンレイクハウスを実装するのに役立ちます。
今回の一般提供は、Cloudera Data Warehouse(CDW)、Cloudera Data Engineering(CDE)、Cloudera Machine Learning(CML)など、CDPの主要データサービス内で実行されるIcebergを対象としています。接続することにより、アナリストやデータサイエンティストは、選択したツールやエンジンを使用し、同じデータに対して簡単に共同作業を行うことができます。データから洞察を抽出するために、ロックインや、不要なデータ変換、ツールやクラウド間のデータ移動はもう必要ありません。
CDPのIcebergでは、以下の主要な機能を利用することができます。
- CDEとCDWによるApache Icebergをサポート:CDEはSpark ETL、CDWはImpalaビジネスインテリジェンスのパターンに従ってクエリを実行する。
- 探索的データサイエンスと可視化:CMLプロジェクトにおいて、自動検出されたCDW接続を介してIcebergテーブルにアクセスできる。
- 豊富なSQL(クエリ、DDL、DML)コマンドのセット:データベースオブジェクトの作成、クエリの実行、データの読み込みと変更、タイムトラベル操作、Hive外部テーブルからIcebergテーブルへの変換など、CDWとCDEのために開発されたSQLコマンドを使用する。
- タイムトラベル:指定した時間やスナップショットIDの時点でクエリを再現し、履歴監査や誤操作のロールバックなどに利用できる。
- インプレーステーブル(スキーマ、パーティション)の進化:テーブルデータの書き換えや新しいテーブルへの移行など、コストをかけずにIcebergのテーブルスキーマやパーティションレイアウトを進化させる。
- SDXインテグレーション (Ranger):Apache Rangerを使用してIcebergのテーブルへのアクセスを管理する。
本内容のブログ記事は2回に分けて、CDPでIcebergを使ってオープンレイクハウスを構築し、データエンジニアリングからデータウェアハウス、機械学習まで、CDPのコンピュートサービスを活用する方法をご紹介します。
前編である今回は、CDPでApache Icebergを使用してオープンレイクハウスを構築する方法、CDEを使用してデータを取り込み変換する方法、Cloudera Data Warehouse上のSQLとBIワークロードにタイムトラベル、パーティションの進化、アクセス制御を行うという点に焦点を当てます。
ソリューション概要
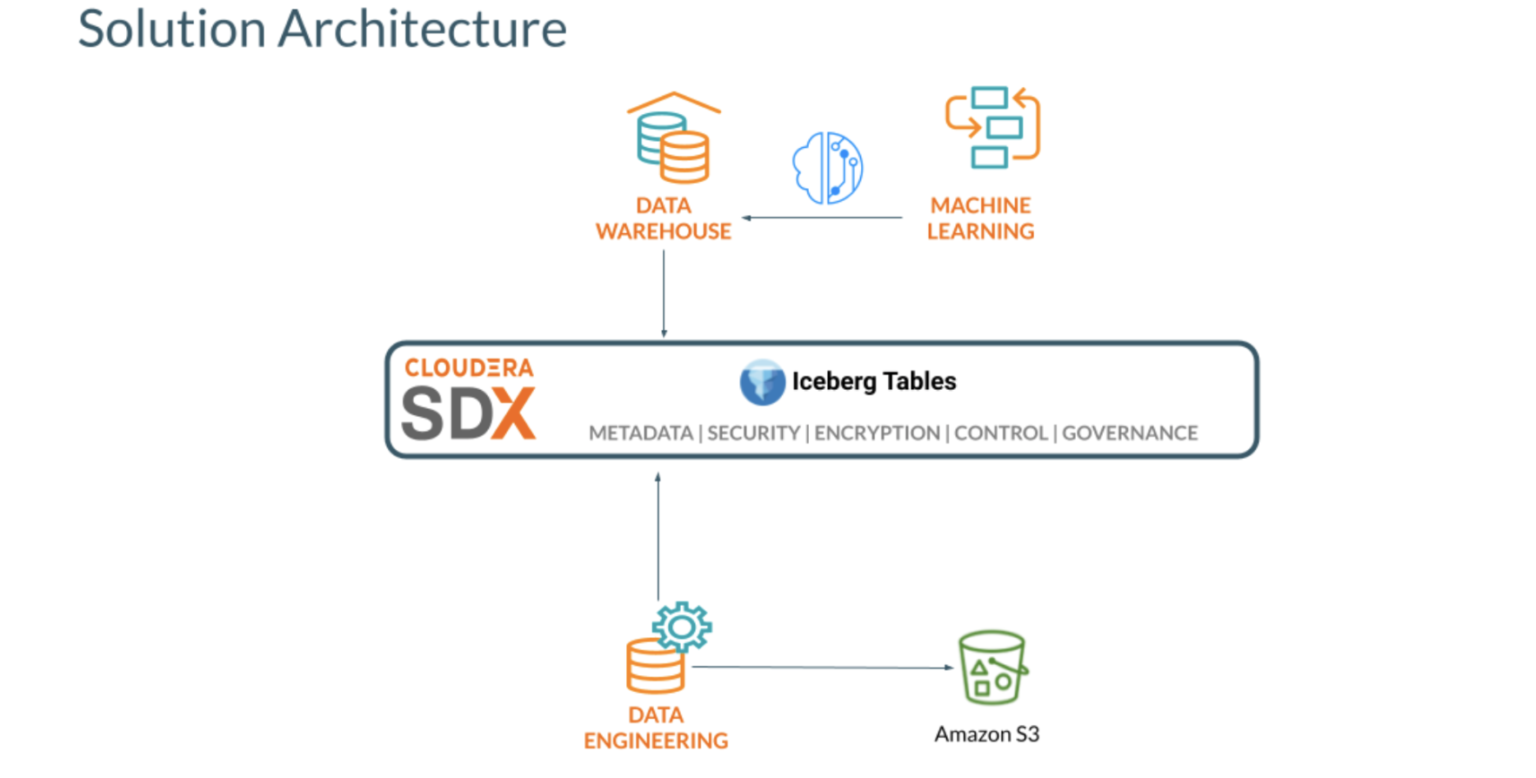
前提条件:
以下のCDPパブリッククラウド(AWS)のデータサービスをプロビジョニングする必要があります。
- Cloudera Data Warehouse Impala Virtual Warehouse
- Cloudera Data Engineering (Spark 3) with Airflow enabled
- Cloudera Machine Learning
CDEにおけるIcebergテーブルへのデータ読み込み
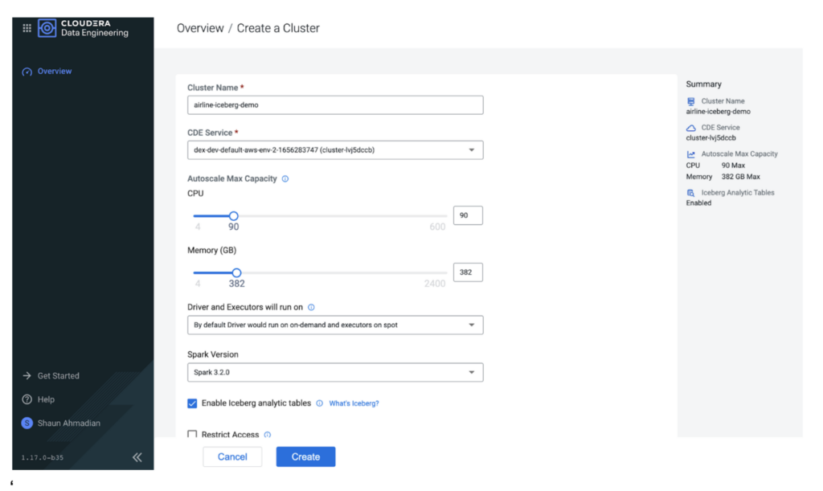
まず、CDEでSpark 3の仮想クラスタ(VC)を作成します。コストを制御するために、仮想クラスタのクォータを調整し、スポットインスタンスを使用することができます。また、Iceberg分析テーブルを有効にするオプションを選択することで、VCがIcebergテーブルを用いるために必要なライブラリを確保できます。
数分後、VCが起動し、新しいSparkジョブをデプロイする準備が整います。
Sparkを使用して一連のテーブル操作を実行するため、Airflowを使用してこれらの操作のパイプラインをオーケストレーションします。
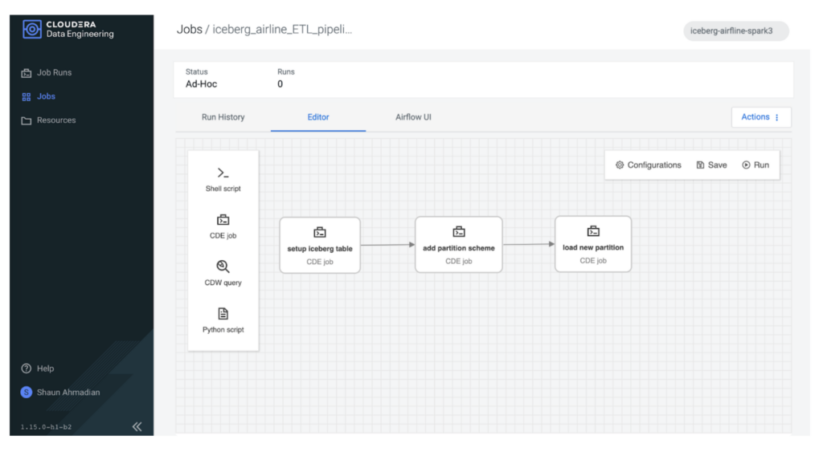
最初のステップは、Icebergテーブルを読み込むことです。Icebergテーブルを直接作成して新しいデータで読み込む以外に、CDPはいくつかのオプションがあります。既存の外部Hiveテーブルをインポートまたは移行することができます。
- インポートすることで、ソースと移行先は、独立した状態に保たれる
- 移行すると、テーブルがIcebergテーブルに変換される
今回のサンプルでは、既存のフライトテーブルを航空会社の Iceberg データベーステーブルにインポートしただけです。
from pyspark.sql import SparkSession import sys spark = SparkSession \ .builder \ .appName("Iceberg prepare tables") \ .config("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkSessionCatalog")\ .config("spark.sql.catalog.spark_catalog.type", "hive")\ .config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")\ .getOrCreate() spark.sql("""CALL spark_catalog.system.snapshot('airlines_csv.flights_external', \ 'airlines_iceberg.flights_v3')""")
インポートしたフライトテーブルには、既存の外部Hiveテーブルと同じデータが含まれており、年ごとの行数をすぐにチェックして確定することができます。
year _c1
1 2008 7009728
2 2007 7453215
3 2006 7141922
4 2005 7140596
5 2004 7129270
6 2003 6488540
7 2002 5271359
8 2001 5967780
9 2000 5683047
…
インプレース・パーティションの進化
次に、最も一般的なデータ管理作業の1つは、テーブルのスキーマを変更することです。通常、パーティションが設定されていない列であれば、この作業は簡単に行えます。しかし、パーティションスキームの変更が必要な場合は、通常、テーブルを1から作り直す必要があります。Iceberg では、これらのテーブル管理操作を最小限の手直しで適用できるため、ビジネス要件に合わせてテーブルを進化させる際に、データ実務者の負担を軽減することができます。
パイプラインの第2段階では、1行のコードを使い、年の列を含むようにパーティションスキームを変更します。
print(f"Alter partition scheme using year \n") spark.sql("""ALTER TABLE airlines_iceberg.flights_v3 \ ADD PARTITION FIELD year""") When describing the table we can see “year” is now a partition column: … # Partition Transform Information # col_name transform_type year IDENTITY …
ETLパイプラインの最終段階では、このパーティションに新しいデータを読み込みます。それでは、Impalaを使用してこのIcebergテーブルを活用し、インタラクティブなBIクエリを実行する方法を見ていきましょう。
CDWでIcebergを使用する
タイムトラベル
Icebergのテーブルにデータが読み込まれたので、Impalaを使ってテーブルにクエリをかけてみます。まずはCDWでHueを開き、CDEでSparkを使って作成したばかりのテーブルにアクセスします。CDWに移動し、Impala Virtual WarehouseでHueを開きます。
まず、テーブルの履歴で次のことを確認します。
DESCRIBE HISTORY flights_v3;
Example Results:
| creation_time | snapshot_id | parent_id | is_current_ancestor |
| 2022-07-20 09:38:27.421000000 | 7445571238522489274 | NULL | TRUE |
| 2022-07-20 09:41:24.610000000 | 1177059607967180436 | 7445571238522489274 | TRUE |
| 2022-07-20 09:50:16.592000000 | 2140091152014174701 | 1177059607967180436 | TRUE |
これで、以下のようにタイムスタンプとsnapshot_idを使用して、異なる時点でテーブルにクエリを実行して結果を確認することができます。
select year, count(*) from flights_v3 FOR SYSTEM_VERSION AS OF 7445571238522489274 group by year order by year desc;
| year | count(*) |
| 2005 | 7140596 |
| 2004 | 7129270 |
| 2003 | 6488540 |
| 2002 | 5271359 |
| 2001 | 5967780 |
| 2000 | 5683047 |
| 1999 | 5527884 |
| 1998 | 5384721 |
| 1997 | 5411843 |
| 1996 | 5351983 |
| 1995 | 5327435 |
最初のスナップショット(7445571238522489274)の時点では、1995年から2005年までのデータがテーブルに入っていることがわかります。2回目のスナップショットの時点のデータを見てみましょう。
select year, count(*) from flights_v3 FOR SYSTEM_VERSION AS OF 1177059607967180436 group by year order by year desc;
| year | count(*) |
| 2006 | 7141922 |
| 2005 | 7140596 |
| 2004 | 7129270 |
| 2003 | 6488540 |
| 2002 | 5271359 |
| 2001 | 5967780 |
| 2000 | 5683047 |
| 1999 | 5527884 |
| 1998 | 5384721 |
| 1997 | 5411843 |
| 1996 | 5351983 |
| 1995 | 5327435 |
これで、2006年時点のデータもテーブルの中に入りました。”FOR SYSTEM_VERSION AS OF <snapshot id>”を使用すると、古いデータを照会することができます。”FOR SYSTEM_TIME AS OF <timestamp>”を使えば、タイムスタンプを使うことも可能です。
インプレース・パーティションの進化
CDE(Spark)のインプレース・パーティションの進化の機能に加えて、CDW(Impala)を使用してインプレース・パーティションの進化を実行することもできます。まず、以下のようにshow create tableコマンドで現在のテーブルのパーティショニングを確認します。
SHOW CREATE TABLE flights_v3;
テーブルが年列でパーティションされていることがわかります。このテーブルのパーティショニングスキームを、年列から、年列と月列によるパーティショニングに変更することができます。新しいデータがテーブルに読み込まれると、その後のすべてのクエリーは、年列だけでなく月列でもパーティションプルーニングを活用できます。
ALTER TABLE flights_v3 SET PARTITION spec (year, month); SHOW CREATE TABLE flights_v3; CREATE EXTERNAL TABLE flights_v3 ( month INT NULL, dayofmonth INT NULL, dayofweek INT NULL, deptime INT NULL, crsdeptime INT NULL, arrtime INT NULL, crsarrtime INT NULL, uniquecarrier STRING NULL, flightnum INT NULL, tailnum STRING NULL, actualelapsedtime INT NULL, crselapsedtime INT NULL, airtime INT NULL, arrdelay INT NULL, depdelay INT NULL, origin STRING NULL, dest STRING NULL, distance INT NULL, taxiin INT NULL, taxiout INT NULL, cancelled INT NULL, cancellationcode STRING NULL, diverted STRING NULL, carrierdelay INT NULL, weatherdelay INT NULL, nasdelay INT NULL, securitydelay INT NULL, lateaircraftdelay INT NULL, year INT NULL ) PARTITIONED BY SPEC ( year, month ) STORED AS ICEBERG LOCATION 's3a://xxxxxx/warehouse/tablespace/external/hive/airlines.db/flights_v3' TBLPROPERTIES ('OBJCAPABILITIES'='EXTREAD,EXTWRITE', 'engine.hive.enabled'='true', 'external.table.purge'='TRUE', 'iceberg.catalog'='hadoop.tables', 'numFiles'='2', 'numFilesErasureCoded'='0', 'totalSize'='6958', 'write.format.default'='parquet')
SDXとの連携によるきめ細かなアクセス制御(Ranger)
Icebergのテーブルを保護するために、以下のように、行と列の両方のセキュリティにレンジャーベースのルールをサポートしています。
taxiout列の列マスキング:
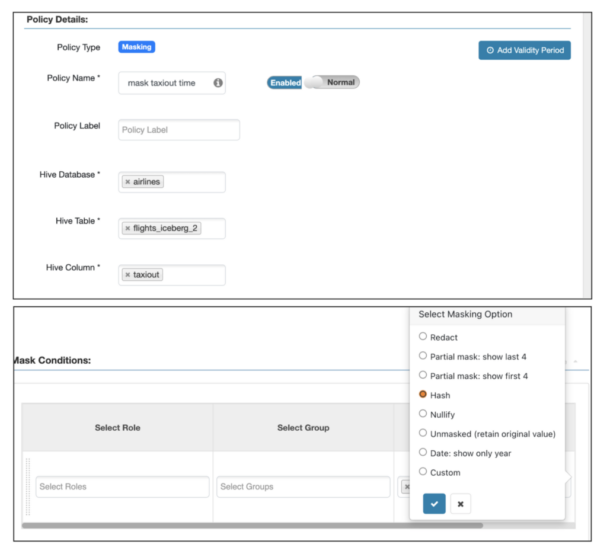
2000年より前の年の行マスキング
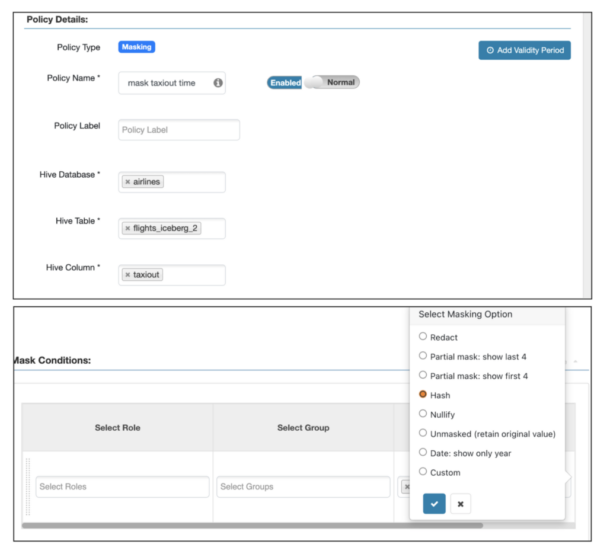
SELECT taxiout FROM flights_v3 limit 10; SELECT distinct (year) FROM flights_v3;
BIクエリ
目的地の空港の国が出発地の空港の国と同じではないフライトとして定義される、すべての国際線を検索するクエリ。
SELECT DISTINCT flightnum, uniquecarrier, origin, dest, month, dayofmonth, `dayofweek` FROM flights_v3, airports_iceberg oa, airports_iceberg da WHERE f.origin = oa.iata and f.dest = da.iata and oa.country <> da.country ORDER BY month ASC, dayofmonth ASC LIMIT 4 ;
| flightnum | uniquecarrier | origin | dest | month | dayofmonth | dayofweek |
| 2280 | XE | BTR | IAH | 1 | 1 | 4 |
| 1673 | DL | ATL | BTR | 1 | 1 | 7 |
| 916 | DL | BTR | ATL | 1 | 1 | 2 |
| 3470 | MQ | BTR | DFW | 1 | 1 | 1 |
乗客名簿データを探索するためのクエリ。例:国際線の乗り継ぎ便があるかどうか?
SELECT * FROM unique_tickets a, flights_v3 o, flights_v3 d, airports oa, airports da WHERE a.leg1flightnum = o.flightnum AND a.leg1uniquecarrier = o.uniquecarrier AND a.leg1origin = o.origin AND a.leg1dest = o.dest AND a.leg1month = o.month AND a.leg1dayofmonth = o.dayofmonth AND a.leg1dayofweek = o.`dayofweek` AND a.leg2flightnum = d.flightnum AND a.leg2uniquecarrier = d.uniquecarrier AND a.leg2origin = d.origin AND a.leg2dest = d.dest AND a.leg2month = d.month AND a.leg2dayofmonth = d.dayofmonth AND a.leg2dayofweek = d.`dayofweek` AND d.origin = oa.iata AND d.dest = da.iata AND oa.country <> da.country ;
まとめ
この前編となるブログでは、Cloudera Data PlatformでApache Icebergを使用して、オープンレイクハウスを構築する方法を紹介しました。ワークフローの例では、Cloudera Data Engineering (CDE) でIcebergテーブルにデータセットを取り込み、Cloudera Data Warehouse (CDW) でタイムトラベルとインプレース・パーティションの進化を行い、FGAC (Fine-grained Access Control) を適用する方法を説明いたしました。後編もお楽しみに!
オープンレイクハウスを構築するには、60日間のトライアルにお申し込みいただき、Cloudera Data Warehouse (CDW)、Cloudera Data Engineering (CDE)、Cloudera Machine Learning (CML) をお試しいただくか、CDPのテストドライブでご確認ください。CDPのApache Icebergについてご興味がある方は、弊社の営業チームまでお問合せをお待ちしております。また、本記事の内容に関するフィードバックはコメント欄へお寄せください。
