

この記事は、2021/10/07に公開された「How Cloudera DataFlow Enables Successful Data Mesh Architectures」の翻訳です。
はじめに
今回ご紹介するのは、Cloudera Data Platform (CDP) で利用できるエッジからクラウドへのストリーミングデータプラットフォームであるCloudera DataFlow (CDF) のもたらす、データの統合、民主化、ファブリックの価値についてとなります。データメッシュアーキテクチャのコンテキストの中で、特定のアーキテクチャが関連する業界の設定やユースケースをご紹介し、ビジネスとテクノロジーの領域に対して提供されるビジネス価値について触れたいと思います。さらに、Clouderaの金融サービス業界のお客様事例とともに、データメッシュアーキテクチャを実現するCDFを選ぶメリットをご紹介します。
このブログでは、データメッシュアーキテクチャとは何か、そしてそのアーキテクチャを実現するために使用できる特定のCDF機能とは何かという概要をお伝えすることに重点を置き、技術的な実装についての詳細は割愛したいと思います。
データメッシュアーキテクチャと必要な機能の概要
データメッシュアーキテクチャとは
データメッシュアーキテクチャのコンセプトは、全く新しいものというわけではありません。その起源は、マイクロサービスアーキテクチャとその設計原則(再利用性、疎結合、自律性、障害耐性、複合性、発見可能性)、およびそれによって解決しようとしている問題につながります。マイクロサービスアーキテクチャのパラダイムを反映して簡単にまとめると、データメッシュのアーキテクチャはデータの所有権を変更せずに、異種かつ個別に管理されているデータドメイン間に統合をもたらし、データの分散を促進することを目的としたものです。
分散型データメッシュアーキテクチャの必要性は、企業がより集中型のデータ管理アーキテクチャを導入する際に直面した課題で明らかです。その課題とは、テクノロジー(例:データエコシステムで使用される複数のポイントソリューションの統合の必要性)と組織管理(例:複数の組織間でのガバナンスモデルの実現が難しい)の両方に起因しているものです。例えば、データマートVSデータウェアハウスの実装(構造化データの時代によく行われたアーキテクチャの議論)、エンタープライズ規模のデータレイクVS小規模で一般的にビジネスユニット固有の「data pond」など、分散化の取り組みは、時代によって異なる名称で登場します。データメッシュアーキテクチャには、メリットとデメリットがあります。しかし、今回はそのメリットやデメリットを評価したり、他のデータアーキテクチャと比較したりするのではなく、Cloudera DataFlow(CDF)がどのように分散アーキテクチャを実現するかに焦点を当ててお話していきたいと思います。
データメッシュの構成要素
データメッシュアーキテクチャを実装するための暗黙の前提は、十分に制限された、個別に管理されたデータドメインの存在です。エンタープライズデータ管理の領域では、このようなデータドメインはAuthoritative Data Domain(ADD)と呼ばれます。EDMカウンシル(Enterprise Data Management Council)によると、Authoritative Data Domainとは「データ管理の管理機関によって指定、検証、承認、実施されたデータドメイン」です。
データメッシュは、通常データプロダクトと呼ばれる「ノード」の集合体として定義することができ、それぞれのノードは4つの主要な記述特性を用いて一意に識別することができます。
- アプリケーションロジック:アプリケーションロジックとは、データ処理の種類を意味し、分析システムや運用システム、そしてデータ入力を取り込み、何らかのビジネスロジックに基づいて変換を行い、データ出力を生成するデータパイプラインまで、あらゆるものが含まれる。
- データおよびメタデータ:アプリケーションロジックに基づいて生成されるデータインプットとデータアウトプット。また、両方に関連するビジネスおよび技術的なメタデータも含まれ、データの発見とデータ資産の定義に関する組織横断的なコンセンサスの達成を可能にする。
- インフラストラクチャー環境:アプリケーションロジックとデータをホストするインフラストラクチャ(プライベートクラウド、パブリッククラウド、またはその両方の組み合わせを含む)。
- データガバナンスモデル:データプロダクトに適用されるデータ管理プログラムの標準、管理およびベストプラクティスを、関連する法的および規制的枠組みとの整合性を保ちながら定義し、実施する組織的構造。データガバナンス機関は、データプロダクトを権威あるデータソース(ADS)として、そのデータ発行者を権威あるプロビジョニングポイント(APP)として指定する。
データメッシュの主な設計原則
ビジョンと目的を達成するために、データメッシュは以下の設計原則に支えられています。
- セルフサービス型データディスカバリー:データコンシューマー(内部ビジネスユーザー、サブスクライブアプリケーション、または外部データ共有パートナーを含む)は、データアクセスの壁を減らすセルフサービスメカニズム(集中型UIポータルなど)を介して、データプロデューサー(通常は権威あるデータソースとして動作するパブリッシングアプリケーション)が提供するデータに簡単にアクセスできるようにする必要がある。
- 包括的なデータセキュリティ:データ資産へのアクセスは、企業全体の標準に基づいたデータ関係者(データ関係者とはデータプロデューサーおよびコンシューマー)の認証を保証し、各データプロダクトのデータタイプ(例:個人情報データ)、およびデータコンシューマーの異なるグループごとのアクセス権に基づくきめ細かいデータアクセス許可を適用する、堅牢なセキュリティメカニズムで管理されなければならない。
- データリネージ:データ構成要素(データコンシューマー、データプロデューサー、データスチュワードを含む)は、データプロデューサーからデータコンシューマーに流れるデータの系統を追跡できる必要があり、場合によっては、与えられたデータプロダクトの境界内で異なるデータ処理のステージの間のデータフローも追跡できる必要がある。後者のデータリネージは、例えばデータエンジニアリングパイプラインのように、データ入力が有向非巡回グラフ(Direct Acyclic Graphs、DAGs)と呼ばれる一連の変換に従ってデータ出力に変換される場合に適用される。
- データ監査:データスチュワードと情報セキュリティアナリストは、データのリネージに加えて、データコンシューマーとデータ資産/データプロダクトのすべてのやりとりを追跡できるようにする必要がある。
- データカタログ:セルフサービスデータポータルを通じて公開されるデータプロダクトを構成するデータ要素について、企業全体で許容される定義を含むデータカタログ。この定義として、データユーザーとデータプロデューサーにメタデータ情報を公開することによって、ビジネスおよび技術的なコンテキストに関する情報になり、利用可能なデータに対する理解を深めるのに役立つ。
- (疎)結合メカニズム:データユーザーが特定のADSにサブスクライブし、それを許可されると、再利用可能な方法でデータを利用できるようにする機能(ポイントツーポイント統合を開発することがない)。ESBのパラダイムに従い、データプロダクトは抽象的に互いに切り離され、公開されたデータプロダクトである論理的なエンドポイントとして結合メカニズムを通じて互いに接続される。
前述の能力は、データメッシュアーキテクチャの技術面のみをカバーするものであり、分散型データアーキテクチャの確立に必要な運用・管理能力は含まれていません。
CDFでデータメッシュアーキテクチャを成功させる
Cloudera DataFlow Platformとは
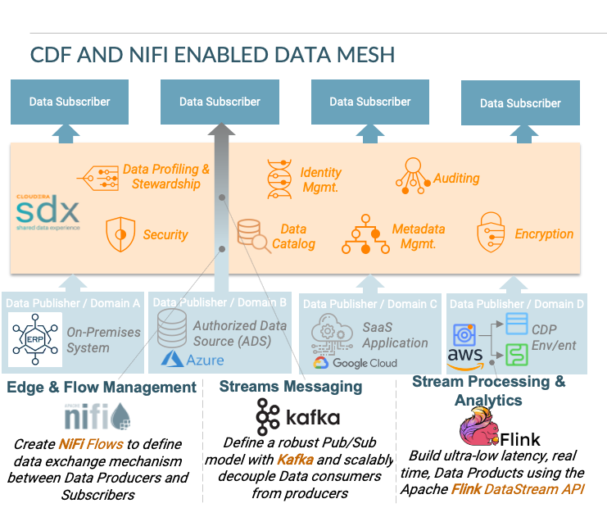
CDFはリアルタイムのストリーミングデータプラットフォームで、エッジ、データセンター、クラウド全体の「データインモーション」を収集、管理、分析、処理します。CDFはApache NiFi、Apache Kafka、Apache Flink等のオープンソースプロジェクトを利用して、エッジおよびフロー管理、ストリーム処理と分析等の主要機能を提供し、エッジからクラウドへのストリーミングアプリケーションを簡単に構築することができます。CDPを搭載したCDFのストリーミングコンポーネントは、エッジ、オンプレミス、パブリック、プライベート、ハイブリッドのどのタイプのクラウド環境にもシームレスに展開することができます。
Apache NiFiは、データの種類、サイズ、起源に関わらず、大量の高速データの収集、変換、移動に活用できるデータ移動・取り込みツールです。 Apache NiFiは、Cloudera Data Platformの広範なデータセキュリティ、ガバナンス、観測機能とともに、データメッシュの実装に最適な候補としての明確なメリットがあります。例を挙げると、集中管理、データのライフサイクルを通じたイベントレベルのデータ実証によるエンドツーエンドのトレーサビリティ、インタラクティブなコマンド&コントロールによるリアルタイムの運用可視化などです。また、スキーマに依存しないこと(スキーマはオプションで、必須ではありません)、メタデータをペイロードから分離することであらゆるタイプのデータを操作できることも、異なるコンテキストやさまざまな範囲でのデータメッシュアーキテクチャの実装を実現することもNiFiの特徴です。
CDFの機能とデータメッシュ実装
CDFには、すでに触れたようにデータメッシュ実装の主要設計原則に沿った多くの機能があります。
データセキュリティ:Cloudera Data Platformのデータ抽象化レイヤーであるShared Data Experience (SDX) は、データセキュリティ、ガバナンス、観測性のための統一されたメカニズムを提供。SDXの一部であるApache Rangerは、異なるデータ構成要素/エンティティ(内部または外部ユーザー)に対して、異なるデータメッシュリソースに対する許可を定義する、きめ細かいプログラム的なメカニズムを提供する。
データリネージ:Apache NiFiとApache Atlas(SDXに含まれる)は、データメッシュを構成するデータプロダクトの境界の内側と外側の両方で、堅牢なデータ証明とデータリネージ機能を提供。データプロダクトの境界外(パブリッシャーとサブスクライバー間)でのデータの移動に関して、Apache NiFiとApache Atlasの両方が、異なるデータ構成要素間を流れるデータのリアルタイムなデータリネージを提供し、データのコンプライアンスと最適化を可能にする。さらに、データプロダクトがCDPエクスペリエンスやSDXと統合するサードパーティソリューション(EMRなど)を使用して構成されている場合、Apache Atlasは、データプロダクトの境界内でリアルタイムのデータリネージを提供する。
データ監査:データのコンプライアンスを確保するために使用できるデータリネージに加えて、NiFiとSDXはデータメッシュに含まれるデータ要素とデータ構成要素のすべての相互作用に関するイベントレベルの詳細を記録するなど、追加のデータ監査機能を提供する。
データカタログ:SDXは、データプロダクトのビジネスおよび技術的なメタデータを取得できる高度なデータカタログ機能を提供。また、自動データ分類、自然言語による検索などの機能も備えている。他の機能と同様に、データカタログはデータプロダクトの固有データと外部データの両方をカバーすることができる。
データ交換メカニズム:すでに述べた通り、NiFiはデータフロープログラミングに基づく非常に堅牢で柔軟なデータフロー管理機能を提供し、システム間のデータルーティング、変換、仲介の組み合わせを可能にする。その結果、NiFiは、異種データの入出力を持つさまざまなタイプのデータプロダクト(これらのデータプロダクトには、運用システムや分析システム、構造化・非構造化データのデータベース、イベントストリームを生成するアプリケーション、あるいはエッジデバイス上のアプリケーションも含まれる)の間でデータメッシュを実装することができる。基盤となるデータ移動メカニズムは、データの検索、操作、ルーティングがどのように行われるかを定義するフロープロセッサと呼ばれるものである。ユーザーは、既存のフロープロセッサを活用するか、または独自のフロープロセッサを構築して、データサブスクライバーとデータコンシューマーを接続するために必要なフロー管理ロジックを実装することができる。
データストリーミング機能:CDFのもう一つの構成要素であるApache Kafkaは、データプロダクトの出力がデータコンシューマーにイベントとしてどのようにストリーミングされるかを定義する、監査可能で再生可能なデータストリームを開発することができる。このデータストリーミング機能により、ストリーミング頻度(ストリームはリアルタイムまたはバッチ)、プロデューサーとコンシューマー間のストリーミングパターン(1対1または1対多)の点で異なる機能特性に対応する、複合ストリーミングアーキテクチャを開発することも可能である。一般的なデータメッシュのアプローチは、データプロダクトの出力をデータイベントとして公開し、Kafkaトピックを通じてデータコンシューマに提供する(Kafkaトピックは、データコンシューマが消費できるようにするために、データプロデューサーのデータ出力を分類して保存する方法)。
データメッシュ実装におけるCDFの価値提案
お客様の課題をCDFでサポート
CDFの機能は、金融サービスや一般消費財の業界におけるデータメッシュの実装に利用されてきました。CDF対応のデータメッシュを実装する前に、組織が直面するよくある課題を次の通りまとめました。
- 価値実現までに時間を要する:疎結合のメカニズムがない場合、データサブスクライバーとデータプロデューサーの間でデータプロダクトへのアクセスを提供することは、システム間のカスタム統合の開発を含む面倒なプロセスとなる。私が関わったデータメッシュのビジネスケースを確立する金融機関の案件では、カスタム統合(または「データフィード」)の開発には、ビジネス要件定義書(BRD)の作成、長い承認サイクル、データフィードを開発するためのスクリプト作成作業、データフィードのエンドツーエンドテストなどの作業が含まれていた。
- メタデータの管理:従来の実装では、データプロダクトの変更(テーブルの更新や新規作成など)と、それに伴うデータフィードの変更に、追加の開発作業とエンタープライズデータカタログへの手作業によるレポートが必要である。
- データディスカバリー:一般的に、レガシーの実装ではデータ検索機能が限られており、ほとんどの場合、データフィードのサブスクライバーはBRDを確認して情報を追跡する必要がある。これは、ポイントツーポイントのデータ交換メカニズムにおける最大の間接的ビジネスコストの1つで、データサブスクライバーがデータの起源やデータの関係を理解するために多くの時間を費やすことで、ビジネスの生産性に多くの遅れを生じさせる。
- データへのアクセス性:カスタムベースの統合は、データプロダクトを接続するために必要な統合メカニズムを提供するが、ポイントツーポイントフィードを作成するためのコストが高すぎるため、通常、個々のユーザーがデータプロダクトにアクセスすることはできない。
お客様事例
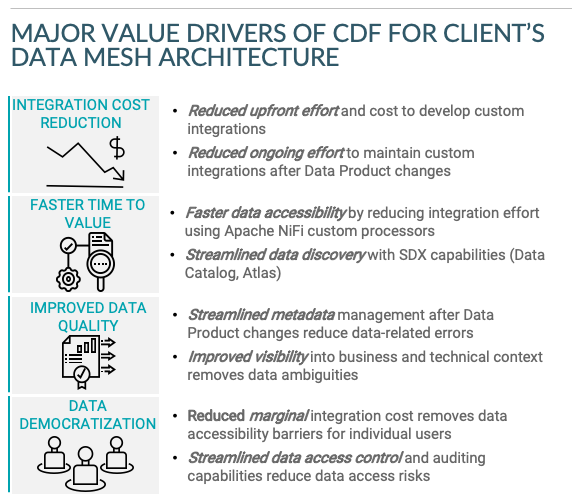
最近、ある大手金融機関のために、データ連携の仕組みとしてApache NiFiを使ったCDFによるデータメッシュアークテクチャの価値を定量化するための提案を作りました。その実装に関連するバリュードライバーは次の通りです。
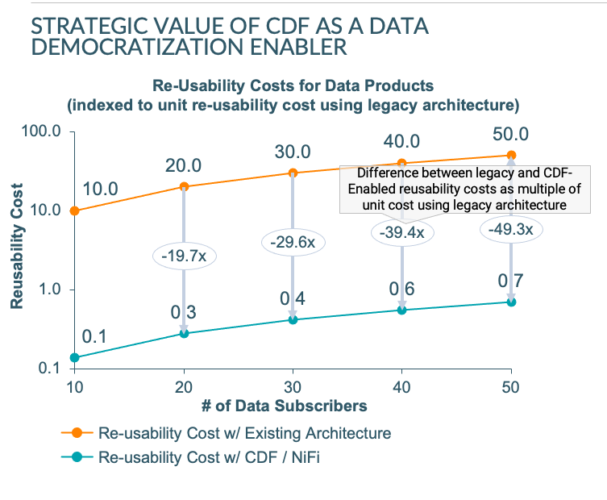
既存のアーキテクチャと比べてみると、CDF対応のデータメッシュはデータプロバイダとデータサブスクライバー/コンシューマー間の再利用性の単価を約99%削減しました。その結果、個々のユーザー/データコンシューマーへのデータ資産のプロビジョニングが可能になりました。これは、データプロバイダとデータサブスクライバー間のカスタム統合を開発するための単価を考えると、他の方法では不可能でした。
まとめ
この記事では、データメッシュアーキテクチャに必要な機能を説明し、CDFプラットフォームがそのアーキテクチャを実装するための技術基盤としてどのような役割を果たすかをご紹介しました。CDFのユニークで他と差別化できる点は、統合されたセキュリティとガバナンスの機能とプラットフォームの多用途性です。
- Shared Data Experience(SDX)により提供される統合されたセキュリティとガバナンス機能は、金融サービスなどの規制された業界におけるデータメッシュの導入を成功させる。
- CDFプラットフォームの多用途性とCDPとの広範な統合により、データメッシュの枠を超えた複雑なユースケースが可能になる。例えば、CDFは顧客分析のためのIoTデータの取り込みと処理、リアルタイムのサイバーセキュリティ分析等、エンタープライズグレードのアプリケーションの実装に使用されている。
CDFプラットフォームについて、詳しくは、https://jp.cloudera.com/products/cdf.htmlをご覧ください。
