

by Ram Venkatesh, and Priyank Patel
この記事は、2022/06/17に公開された「The Future of the Data Lakehouse – Open」の翻訳です。
Clouderaのお客様は、地球上で最大規模のデータレイクを運用しています。これらのデータレイクは、エンタープライズデータウェアハウスを含む、ミッションクリティカルな大規模データ分析、ビジネスインテリジェンス(BI)、機械学習のユースケースを支えています。近年、データレイク内のデータをテーブルフォーマットで分析するこのアーキテクチャパターンを表現するために、「データレイクハウス」という用語が生まれました。そんな中で、データレイクハウスの取り入れを急ぐあまり、多くのベンダーは、データアーキテクチャのオープン性こそが、その耐久性と長寿命を保証するという事実を見失っています。
データウェアハウスとデータレイクについて
データレイクとデータウェアハウスは、大量かつ多様なデータを一元的に管理するものです。しかし、そのアーキテクチャの世界観は大きく異なります。ウェアハウスはSQL分析用に垂直統合されていますが、レイクはSQL以外の分析手法の柔軟性を優先しています。
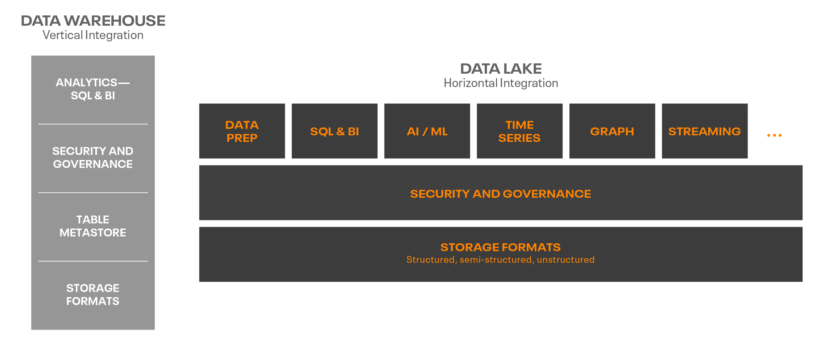
データレイクの柔軟な分析と、データウェアハウスのシンプルで高速なSQLという、両方の利点を実現するために、企業はデータウェアハウスを補完するデータレイクを導入しています。データレイクからデータウェアハウスシステムに、抽出・変換・書き出し(ETL)する、またはELTパイプラインの最後のステップとしてデータを供給することがよくあります。そうすることで、結果的にデータがウェアハウスにロックインされることを受け入れてきました。
しかし、もっと良い方法が登場しました。過去10年間におけるデータプラットフォームのヒット作の1つであるHiveメタストアの登場です。ユースケースが成熟するにつれ、効率的でインタラクティブなBI分析と、データを修正するためのトランザクションセマンティックスの両方が必要であることが分かってきました。
レイクハウスのイテレーション
Hiveメタストアの第1世代は、データレイク上でSQLを効率的に実行するためのパフォーマンスに関する考慮事項に対処しようと試みました。データレイクの構造を記述するためのデータベース、スキーマ、テーブルの概念を提供し、BIツールが効率的にデータを横断的にアクセスできるようにしました。また、データの論理的・物理的レイアウトを記述するメタデータを追加し、コストベースオプティマイザ(CBO)、ダイナミックパーティション・プルーニング、SQL分析を対象とした多くの主要な性能改善を可能にしました。
Hiveメタストアの第2世代では、Hive ACIDによるトランザクション更新のサポートが追加されました。その当時まだ名前はついていませんでしたが、レイクハウスは非常に繁栄していました。トランザクションは継続的なデータ取り込みと挿入/更新/削除(もしくはMERGE処理)のユースケースを可能にし、データウェアハウススタイルのクエリ、機能、他のウェアハウスシステムからデータレイクへの移行を開放しました。これは、多くのお客様にとって非常に価値のあるものでした。
Delta Lakeのようなプロジェクトは、この問題を解決するために異なるアプローチを取りました。Delta Lakeは、レイク内のデータにトランザクションのサポートを追加。これにより、データのキュレーションが可能になり、データウェアハウス形式の分析をデータレイクで実行することができるようになったのです。
この時系列のどこかで、このアーキテクチャパターンに対して「データレイクハウス」という名称が作られました。レイクハウスは、このパターンを簡潔に定義する素晴らしい方法であり、ユーザーや業界の間で急速に認知度が高まったと考えています。
お客様の声
ここ数年、新しいデータタイプが生まれ、分析を簡素化する新しいデータ処理エンジンが登場するにつれ、企業は、両者の長所を生かすには、分析エンジンの柔軟性が本当に必要だと考えるようになりました。企業にとって価値のある大規模なデータを管理するのであれば、異なる分析エンジンやベンダーを選択できるオープンさが必要なのです。
レイクハウスパターンは、レイクはオープンであるが、レイクハウスはオープンでない、という決定的な矛盾を抱えながら実装されています。
HiveメタストアはHiveを中心に進化し、その後ImpalaやSparkなどのエンジンが追加されました。Delta LakeはSparkを中心とした進化を遂げました。テーブルフォーマットで主要なものとは異なるエンジンを選択する自由が必要な場合、選択肢は極端に減少します。
お客様は、最初からもっと多くのことを求めていました。より多くのフォーマット、より多くのエンジン、より多くの相互運用性。現在、Hiveメタストアは複数のエンジン、複数のストレージオプションで利用されています。HiveやSparkはもちろん、PrestoやImpalaなど、さまざまなものがあります。Hiveメタストアはこれらのユースケースをサポートするために有機的に進化してきたため、統合は複雑でエラーが発生しやすいことが多かったのです。
このような相互運用性の必要性を考慮して設計されたオープンデータレイクハウスは、このアーキテクチャ上の問題の根底から問うものとなりました。全てがコミュニティ主導のイノベーションとは、現実世界の問題を現実的な方法で最善のツールを使って解決することであり、ベンダーロックインを克服することなのです。
オープンレイクハウスとApache Icebergの誕生
Apache Icebergは開発当初から、複数の分析エンジン間で容易に相互運用できること、そしてクラウドネイティブな規模であることを目標に開発されました。このイノベーションが生まれたNetflixは、100PB規模のS3データレイクをデータウェアハウスに組み込む必要があった最たる例といえます。クラウドネイティブのテーブルフォーマットは、その作成者によってApache Icebergにオープンソース化されました。
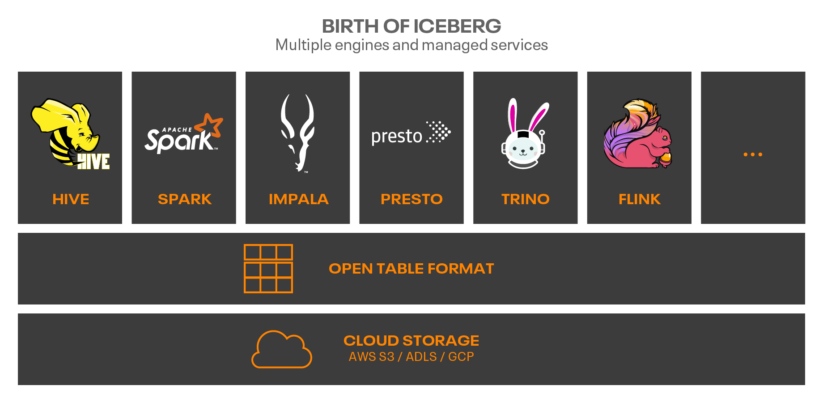
Apache Icebergの真の力は、そのコミュニティです。過去3年間で、Apache Icebergは、活発なコミュニティにおける一流の統合を実現しました。
- データ処理およびSQLエンジン:Hive、Impala、Spark、PrestoDB、Trino、Flink
- 複数のファイルフォーマット:Parquet、AVRO、ORC
- コミュニティでの大規模な採用例:Apple、LinkedIn、Adobe、Netflix、Expedia、その他
- AWS Athena、Cloudera、EMR、Snowflake、Tencent、Alibaba、Dremio、Starburstのマネージドサービス
この多様なコミュニティを成長させているのは、データレイクがデータウェアハウスに取って代わられるように進化しつつ、分析上の柔軟性とエンジン間のオープン性を維持するという、何千社もの企業のニーズの集合体であることです。これによって、将来にわたって無限の分析的柔軟性を提供するオープンレイクハウスが実現するのです。
どのようにIcebergを受け入れているのか?
Clouderaでは、オープンソースのルーツを誇りにしています。そして、コミュニティをより豊かにする取り組みを続けています。2021年以降、私たちはImpala、Hive、Spark、Icebergに関して、成長するIcebergコミュニティに何百ものコントリビュートを行いきました。Hiveメタストアを拡張し、多くのオープンソースエンジンにIcebergのテーブルを活用するための統合機能を追加しました。2022年初頭、Cloudera Data PlatformでApache IcebergのTechnical Preview (TP)が利用可能になり、Clouderaのお客様は、データウェアハウス、データエンジニアリング、機械学習サービスにおいてIcebergのスキーマ進化とタイムトラベル機能の価値を実感することができるようになりました。
当社のお客様は、最新のBI、AI/ML、データサイエンスなど、分析ニーズが急速に進化していることを語っています。Apache Icebergを搭載したオープンデータレイクハウスを選択することで、企業は、分析のための自由な選択を手に入れることができます。
詳しく知りたい方は、Apache Icebergの共同開発者であるRyan Blue氏とNetflixのビッグデータコンピュートリードであるAnjali Norwood氏によるWebセミナーのアーカイブ(英語)も合わせてご覧ください。
