

by Peter Ableda
この記事は、2023/08/28 に公開された「Deploying an LLM ChatBot Augmented with Enterprise Data」の翻訳です。
ChatGPT のリリースは、大規模言語モデル (LLM) を基盤とするユースケースへの関心と期待を、これまでにない水準へ押し上げました。どの企業も、社内業務の改善や、ユーザーおよび顧客とのやり取りのレベルアップを目的に、LLM ベースのサービスの実験と検証に取り組み、最終的なリリースを目指しています。
Cloudera はこれまでお客様と協力し、この新たなイノベーションから利益を得ていただけるように取り組んできました。当シリーズの第一弾となるこの記事では、これらの新技術を企業が採用する際の課題を共有し、安全かつ制御されたやり方で導入することが可能な方法を提案します。
強力な LLM は、ライフスタイルに関するアドバイスから、トランスフォーマーアーキテクチャの設計に役立つ情報まで、多様なテーマをカバーすることが可能です。しかし、企業にはもっと具体的なニーズがあります。企業それぞれのコンテキストに応じた答えが必要なのです。例えば、社員の1人が出張時の昼食の経費の上限について質問する場合、もし LLM がその会社の特定のポリシーへのアクセス権を持っていなければ、質問した社員は必要な答えを得ることはできません。ここに大きく立ちはだかるのが、プライバシーの問題です。多くの企業は、データ保全のため社内のナレッジベースを外部のプロバイダーと共有することに慎重だからです。アウトソーシングとデータ保護の間のこの微妙なバランスは、依然として極めて重要な懸念事項です。また、LLMの不透明性も、安全性への懸念を増幅させます。特に、そのモデルが訓練データ、プロセス、バイアス軽減に関して透明性を欠く場合はなおさらです。
良い話もあります。オープンソースの力を使えば企業が求めるあらゆる要件を実現できることです。次のセクションでは、当社の最新の応用機械学習プロトタイプ (AMP) である「企業データで拡張されたLLMチャットボット」について一通り解説します。この AMP は、チャットボットアプリケーションを企業のナレッジベースを用いて拡張し、コンテキストを認識できるようにする方法の実例を示しています。この方法は、エアギャップ環境さえも含むあらゆる場所でプライベートにデプロイが可能です。何よりも、この AMP は100%オープンソース技術を用いて構築されています。
この AMP は CML 内でアプリケーションをデプロイし、2つの異なる回答を生成します。1つは、LLM の訓練に用いられたナレッジベースのみを使用するもの、もう1つは、Cloudera のコンテキストに基づくものです。
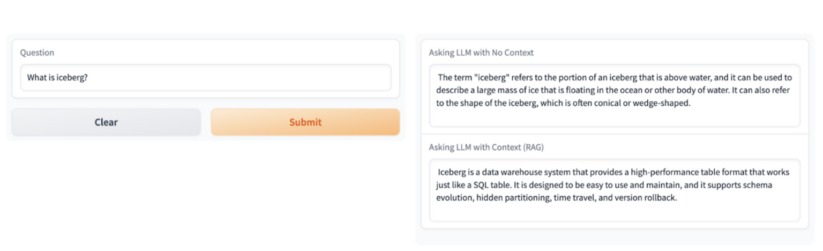
例えば、「Iceberg (氷山) とは何ですか?」と質問した場合、1つめの回答は事実に基づき、水に浮かぶ大きな氷の塊であると説明されます。ほとんどの人にとって、これは妥当な答えです。しかし、質問者がデータの専門家であるなら、Icebergはまったく別のものです。データの世界では、Icebergはたいていの場合、オープンレイクハウスの基盤となっているオープンソースの高性能テーブルフォーマットを指します。
次のセクションでは、AMPの実装に関する重要な詳細を取り上げます。
LLM AMP
AMP は、企業ユースケースを促進するために特別に設計された、構築済みのエンドツーエンドMLプロジェクトです。Cloudera Machine Learning (CML) 内では、AMP カタログからML プロジェクト一式をワンクリックで選択し、デプロイすることができます。
すべての AMP はオープンソースであり、GitHub で入手可能です。そのため、Cloudera Machine Learning へのアクセス権がなくても、プロジェクトにアクセスし、少し手を加えるだけでノートPC やその他のプラットフォーム上でデプロイすることができます。
デプロイすると、AMP は一連のステップを実行し、エンドツーエンドのユースケースを完成させるために必要なすべての設定とプロビジョニングを行います。次のセクションからは、このプロセスの主なステップについて解説します。
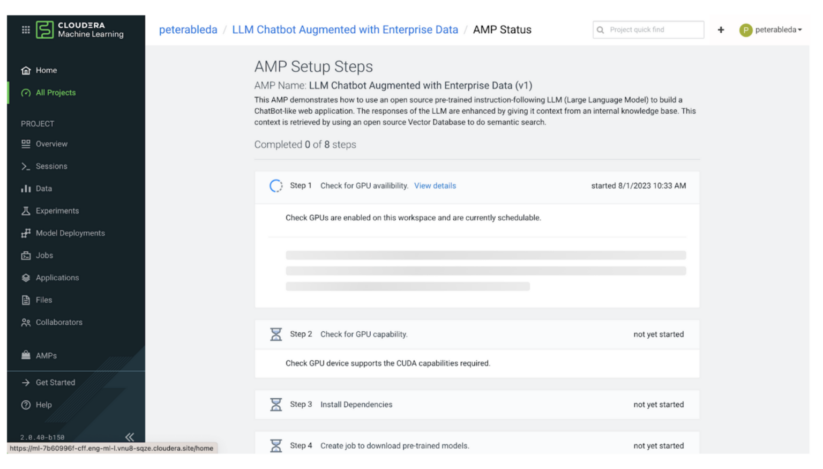
ステップ1と2では、AMP が一連のチェックを実行し、現在の環境にこのユースケースをホストするのに必要な計算リソースがあることを確認します。この AMP は最先端のオープンソース LLM 技術で構築されており、CUDA計算能力 5.0 以上を持つ NVIDIA GPU が最低1つ必要です (V100、A100、T4 GPUなど)。
必要な計算リソースを有する環境であることを確認すると、AMP はプロジェクトセットアップに進みます。ステップ3において、AMP はトランスフォーマーのように requirements.txt ファイルから依存関係をインストールします。次に、ステップ4と5で、HuggingFace から構成済みのモデルをダウンロードします。AMPは、テキストを高次元ベクトル空間にマッピングする (埋め込み) ためのsentence-transformer モデルを使用して類似性検索の実行を可能にすると共に、質問応答 LLM として H2O モデルを使用します。
ステップ6と7では、プロトタイプの ETL 部分を実行します。AMP はこれらのステップの間に、意味検索用の埋め込みとして企業ナレッジベースをVector DB に追加します。

厳密に言えばこれは AMP の一部ではありませんが、AMP のチャットボット応答の品質がコンテキスト用に与えられるデータの品質によって大きく左右されることは、注目に値します。そのため、チャットボットからの高品質な応答を確保するためには、ナレッジベースを整理し、クリーンな状態にしておくことが不可欠です。
ナレッジベースには Cloudera ドキュメントの各ページが使用されます。AMP はそのデータをチャンクして、オープンソースの埋め込みモデル (前のステップでダウンロードしたもの) にロードし、埋め込みを Milvus Vector Database に挿入します。
ステップ8では、ユーザーと直接向き合うチャットボットアプリケーションをデプロイし、プロトタイプを完成させます。下の画像は、チャットボットアプリケーションが生成する2つの回答、 1つは企業のコンテキストあり、もう1つは企業コンテキストなしを示しています。

アプリケーションは質問を受けると、まず赤いパスに従ってオープンソース命令チューニング LLM に質問を渡し、回答を生成します。
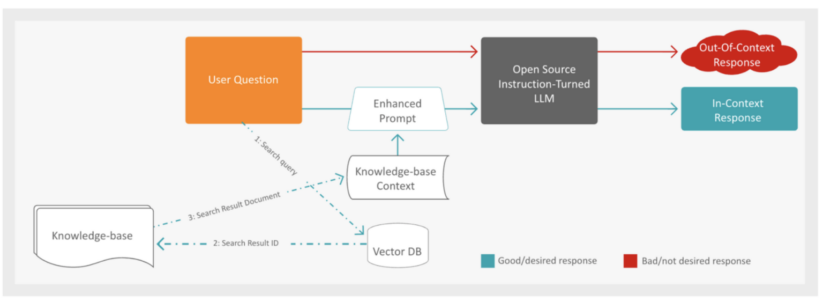
ユーザーの質問に反応して事実に基づく回答を生成するRAG (検索により強化した文章生成) のプロセスには、いくつかのステップがあります。まず、システムはナレッジベースからの追加コンテキストを用いて、ユーザーの質問を拡張します。これを実現するため、Vector Database を検索してユーザーの質問と意味的に最も近いドキュメントを探し、埋め込みを活用して関連するコンテンツを見つけます。
最も近いドキュメントが特定されると、システムはドキュメントID と検索応答で得られた埋め込みを用いてコンテキストを検索します。これでコンテキストが強化されたら、次のステップは、事実に基づく回答を生成するため、LLM に拡張されたプロンプトを送信することです。このプロンプトには、検索されたコンテキストと元のユーザーの質問の両方が含まれます。
最後に、生成された LLM からの応答がウェブアプリケーションを通じてユーザーに提示され、問い合わせに対する包括的で正確な回答が提供されます。このような多段階のアプローチにより、十分な情報による裏付けとコンテキスト上の関連性が確保された回答が保証され、全体的なユーザーエクスペリエンスが向上します。
上記のすべてのステップが完了すると、プロトタイプのエンドツーエンドのデプロイが完全に機能するようになります。
LLM AMP チャットボットをデプロイし、ユーザー体験を向上させる
Cloudera Machine Learning (CML) へ行き、AMPカタログにアクセスしましょう。ワンクリックするだけで、プロジェクト一式を選択してデプロイし、ユースケースを簡単に開始することができます。CMLへのアクセス権を持っていない場合も心配はありません!このAMPはオープンソースであり、GitHubから入手できます。ノートPC やお好きなプラットフォームで、最小限の調整を行うだけでデプロイすることが可能です。こちらからGitHubリポジトリにアクセスしてください。
Cloudera がお客様に提供している AI ソリューションについて詳しく知りたい場合は、当社の「エンタープライズ AI」ページを参照してください。
このシリーズの次の記事では、LLM AMP を組織固有のニーズに合わせてカスタマイズする方法について、掘り下げて解説します。企業ナレッジベースをチャットボットへシームレスに統合し、パーソナライズされたコンテキスト上関連性のある回答を提供する方法をご確認ください。実用的な洞察、ステップバイステップ方式のガイダンス、そして AI ユースケースを強化するための実例のご紹介を予定しています。
